
Think of data management in clinical trials as the meticulous, behind-the-scenes work that makes or breaks medical research. It’s the entire process of gathering, cleaning, and protecting every piece of information collected during a study. This isn't just about good housekeeping; it’s a non-negotiable discipline that directly underpins patient safety, the validity of a trial's findings, and whether a new therapy ever gets approved.
The Blueprint for Reliable Medical Research
Data management in clinical trials is so much more than just plugging numbers into a database. It's a highly structured system for turning the raw, often messy, data from a study into a pristine, reliable, and statistically sound dataset.
Picture an air traffic control system at a major airport. The controllers have to track every single plane—its altitude, speed, and flight path—to keep everyone safe. In the same way, clinical data managers meticulously track every data point, from a patient's initial consent form to the results of their very last lab test.
This rigorous oversight ensures that all information is captured correctly, cross-checked against original source documents, and stored securely. Without it, the study's conclusions could be built on a shaky foundation, leading to wrong answers about a new treatment's safety or effectiveness. The real goal here is to transform chaos into order—to create a clean, locked dataset that's ready for the statisticians.
The Four Pillars of Clinical Data Management
A solid data management strategy rests on a few core principles. These aren't just bureaucratic steps; they represent a deep commitment to scientific quality and ethical conduct.
Here’s a breakdown of the foundational components that ensure a trial’s integrity from start to finish.
| Pillar | Description | Primary Objective |
|---|---|---|
| Data Collection | The systematic process of gathering data from various sources (eCRFs, labs, patient diaries) using a predefined plan. | To capture complete and accurate information as specified in the trial protocol. |
| Data Cleaning & Validation | A rigorous review process to identify, question, and resolve inconsistencies, errors, or missing data. | To ensure the dataset is logical, consistent, and free from correctable errors. |
| Regulatory Compliance | Adhering to established industry standards and regulations, like GCP and FDA 21 CFR Part 11. | To protect patient rights, ensure data credibility, and meet legal requirements for submission. |
| Data Security & Archiving | Implementing measures to protect sensitive data from unauthorized access and ensuring its long-term preservation. | To maintain patient confidentiality and create an auditable record for future review. |
Each pillar supports the others, creating a robust framework that allows researchers and regulators to trust the final results.
This diagram offers a great visual of how these moving parts connect and flow within a modern clinical trial.

As you can see, it's a cyclical, collaborative effort. Data comes in, gets checked, queries are sent back to the clinical sites to be resolved, and the corrected data flows back into the central database, getting cleaner with each cycle.
Ultimately, the entire purpose of clinical data management is to guarantee that the conclusions drawn from a study are fully supported by the data itself. Every single step is designed to remove doubt and error, making the final analysis as strong as possible.
This systematic approach is precisely why regulatory bodies like the FDA and EMA can have confidence in a trial's results. It provides a transparent, traceable path proving the data is not only accurate but was also handled ethically and correctly from day one. Without it, modern medical breakthroughs simply wouldn't happen.
The Clinical Data Management Workflow Unpacked
The journey of clinical trial data isn’t a haphazard collection of facts; it’s a meticulously planned expedition. The success of data management in clinical trials depends entirely on a structured workflow that guides every single data point—from the moment it’s recorded at a patient's side to its final, locked-down home in an analysis-ready database. This whole process is designed to ensure that when statisticians get their hands on the data, it's as clean, accurate, and trustworthy as humanly possible.
It all starts long before the first patient even walks through the clinic door. The foundational document is the Data Management Plan (DMP), which acts as the master blueprint for the entire operation. This critical document lays out every single rule for handling data, covering everything from collection methods and validation checks to the final steps for locking the database. Think of it as the constitution for the trial's data; it ensures everyone is playing by the same rules.
From Blueprint to Database Build
Once the DMP is signed off, the team gets to work building the digital home for all this data. This usually means configuring a clinical database inside an Electronic Data Capture (EDC) system. This isn't just about creating a few empty fields. It's about carefully translating the trial's protocol into a functional, intuitive interface for the people who will use it every day.
The core of the database build is creating the electronic Case Report Forms (eCRFs). These are the digital equivalents of the paper forms and questionnaires used to capture patient data. A well-designed eCRF is easy for site staff to use while also being smart enough to catch obvious mistakes right at the source.
A make-or-break step here is User Acceptance Testing (UAT). Before the system ever sees real patient data, it goes through a rigorous test run. Team members will act as site coordinators, entering both perfect and intentionally flawed data. The goal is to see if the system behaves as expected and to squash any bugs before the trial goes live.
The Lifecycle of a Data Point
When the trial finally kicks off, the workflow shifts into high gear. The process of collecting, entering, and cleaning data becomes a carefully managed, cyclical routine. This infographic breaks down the essential flow from the moment a patient is enrolled to the point their data is verified.
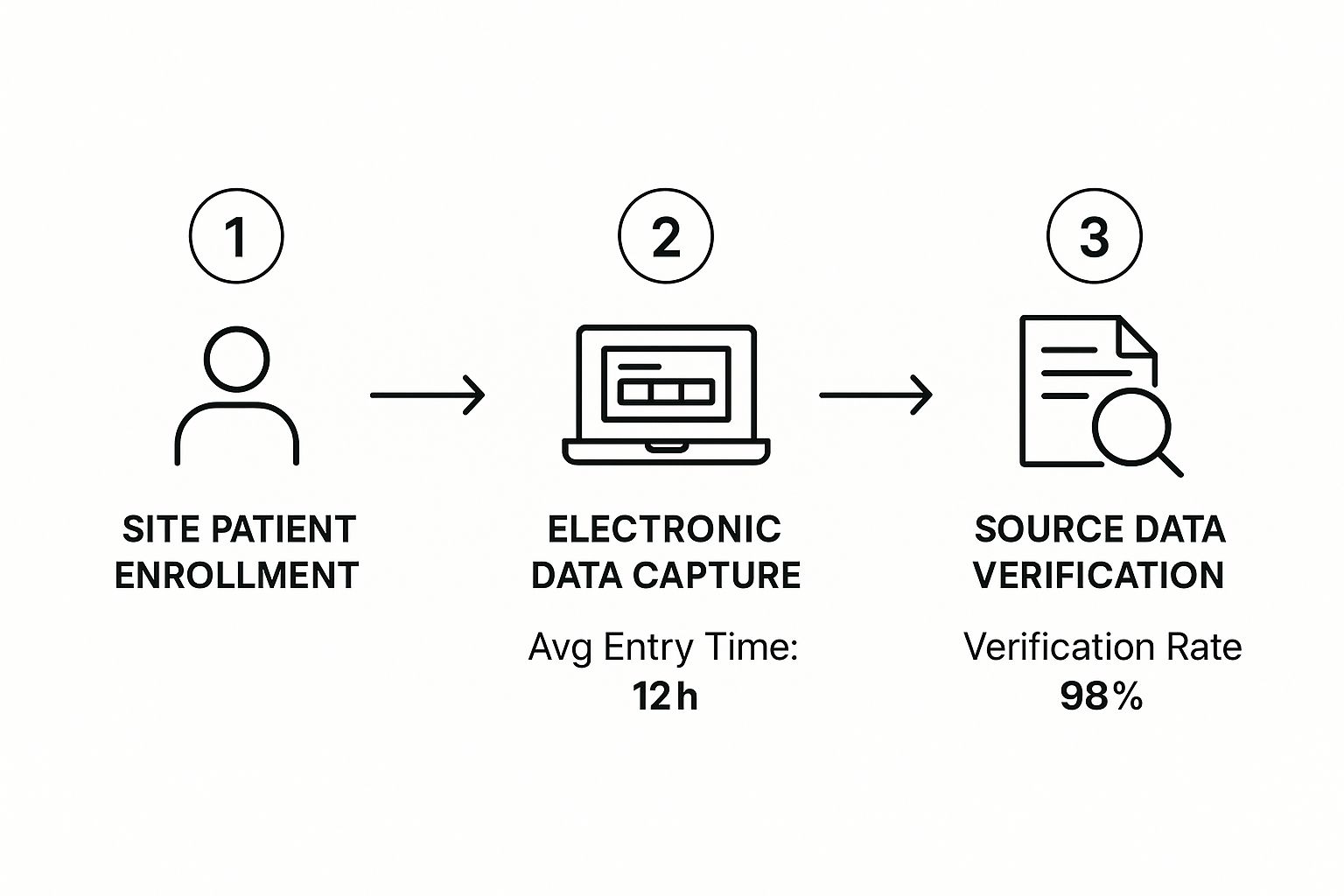
That 98% verification rate isn't just a nice-to-have metric. It shows how modern systems have baked this critical quality control step right into the workflow, safeguarding data integrity from day one.
Let’s take a closer look at what’s happening during this busy phase:
- Data Entry: At the clinical site, staff enter patient information directly into the eCRFs in the EDC system. The industry standard is to encourage prompt data entry to avoid backlogs and get the review process started quickly.
- Automated Validation: As soon as data is entered, the EDC system runs a series of pre-programmed checks. For instance, it might flag a patient’s age if someone types "200" or make sure a treatment end date doesn't come before its start date.
- Manual Review & Query Resolution: Data managers then review the incoming data, looking for more nuanced issues that an automated check might miss. When they find a potential error or inconsistency, they issue a query—a formal request sent back to the site asking for a correction or clarification.
- Source Data Verification (SDV): To close the loop, clinical monitors visit the trial sites. Their job is to compare the data entered into the EDC directly against the original source documents, like patient charts or lab reports. This confirms that what's in the system is a perfect match to the real-world source.
This cycle of entry, validation, and verification is repeated for every patient, over and over, for the entire duration of the study.
Culminating in the Database Lock
The final, most critical milestone in the whole workflow is the database lock. This is the point of no return. All data collection, cleaning, and corrections officially stop, and the database is frozen to prevent any further changes. It’s a huge moment for the entire study team.
Before the lock can happen, a long checklist of pre-lock tasks must be completed:
- All expected data must be in the system.
- Every single query must be resolved and closed.
- All data from external sources (like central labs) has to be imported and reconciled.
- Key stakeholders, especially the Principal Investigator, must provide all required signatures and approvals.
Once every box is ticked, the "hard lock" is applied. This pristine, final dataset is then handed over to the biostatistics team. From this point forward, this locked data becomes the single source of truth for every statistical analysis, every report, and, ultimately, the submission to regulatory agencies.
How to Ensure Data Quality and Integrity

Excellent data in a clinical trial doesn't just happen. It's the product of meticulous, proactive work designed to protect the accuracy of every single piece of information. Think of it like building a house—if the foundation has even a tiny crack, the entire structure is compromised. In the world of data management in clinical trials, that foundation is built with careful engineering, not hope.
Why the intensity? Because even a seemingly minor slip-up can have huge consequences. Imagine a blood pressure reading is off by a decimal point or a patient's adverse reaction is miscategorized. These small errors can snowball, not only undermining the trial's results but potentially putting patient safety at risk. The entire quality assurance process is built to catch these issues before they can do any harm.
Creating the Data Validation Plan
Your first line of defense is a solid Data Validation Plan (DVP). This document is your quality control blueprint, laying out all the rules the data needs to follow. It gets incredibly specific, defining exactly what "clean" and "logical" data looks like for your particular study protocol.
A good DVP will always specify checks for:
- Range Checks: Making sure values are plausible. For example, a patient’s age can’t be 200.
- Format Checks: Verifying data is entered correctly, like ensuring all dates follow a consistent DD-MM-YYYY format.
- Consistency Checks: Cross-referencing related data to catch contradictions. A follow-up visit date can't come before the initial appointment.
- Logic Checks: Applying the study's own rules to the data. A patient in the placebo group shouldn't have a record showing they received the active drug.
These rules aren't just written down and forgotten. They’re programmed directly into the Electronic Data Capture (EDC) system as automated edit checks. These act like digital guardrails, flagging potential mistakes the moment data is entered.
The Cycle of Discrepancy Management
When an automated check flags a problem, it kicks off a critical process called discrepancy management. This isn't about just pointing out errors; it's a formal investigation. When data gets flagged, the system generates a query that is sent directly to the staff at the clinical site. This formal request for clarification or correction creates a transparent, fully auditable record of how the issue was resolved.
This constant cycle—data entry, automated check, query, and resolution—is the engine that powers data cleaning. It ensures the dataset gets cleaner and more reliable as the trial progresses. The need for these strict processes has helped fuel massive growth in the field. Clinical data management services are now essential to a global research ecosystem of over 450,000 registered trials. In fact, the sector is expected to grow at a 5.7% CAGR through 2030, largely because trials are getting more complex and regulators are more focused on data integrity than ever before. For a closer look at this growth, you can discover more about the growth of these critical services and their role in modern research.
To keep data quality high, you have to lean on robust cleaning processes. For a deeper look at the nuts and bolts, it's worth exploring these essential data cleaning techniques.
Verifying Data Against the Source
The final piece of the quality puzzle is making sure the data in your EDC system is a perfect mirror of the original source—the actual patient charts, lab reports, and other raw documents. The old-school way of doing this was 100% Source Data Verification (SDV), where monitors would painstakingly check every single data point.
But the industry has wisely moved toward a smarter, more modern approach: Risk-Based Monitoring (RBM). Instead of checking everything, RBM focuses verification efforts on the data that truly matters—the information that most directly impacts patient safety and the trial's primary goals.
This risk-based strategy doesn't cut corners on quality. It just allocates resources more intelligently, putting the most scrutiny where it's needed most. This makes the entire verification process faster and more effective. By combining automated checks, disciplined discrepancy management, and strategic verification, data teams build a dataset that isn't just clean, but one you can truly trust.
Navigating the Maze of Regulatory and Compliance Standards
Proper data management in clinical trials is about much more than just keeping information tidy. It's about rigorously following a non-negotiable set of ethical and scientific rules. Think of these regulations as the bedrock of clinical research; they aren't just suggestions. They are the core principles that protect patients and ensure the data presented to agencies like the FDA is completely credible.
Getting compliance right means looking past the checklists. You have to understand the why behind the rules. At their heart, these regulations exist to safeguard two things: the rights and well-being of the people participating in the trial, and the scientific integrity of the final results. Without this solid framework, the entire enterprise of medical research would crumble.
The Cornerstone: Good Clinical Practice (GCP)
The single most important set of guidelines is Good Clinical Practice (GCP). This is the international gold standard for the ethics and quality of any trial involving human subjects—from design and execution to recording and reporting. Following GCP gives the public confidence that the rights, safety, and well-being of trial participants are protected, aligning with principles first laid out in the Declaration of Helsinki.
GCP insists that all clinical trial data must be:
- Accurate: It has to be a true reflection of what actually happened.
- Complete: No crucial information can be left out.
- Verifiable: You must be able to trace it back to the original source documents.
Essentially, this standard holds every part of the data management process to a high standard of transparency and accountability.
FDA 21 CFR Part 11 and the Digital Revolution
When clinical trials started shifting from paper binders to digital systems, a new rulebook was needed. The FDA’s 21 CFR Part 11 lays out the ground rules for when electronic records and signatures can be considered as trustworthy and reliable as their paper counterparts. This is absolutely critical for any trial using an Electronic Data Capture (EDC) system.
In plain English, this means your software must have secure, computer-generated, time-stamped audit trails. These trails automatically record who did what, and when, for every piece of data created, changed, or deleted. It’s the digital version of an un-editable, permanent logbook.
This regulation is what prevents electronic data from being tampered with, creating a crystal-clear chain of custody from the moment data is entered to the final database lock. Similarly, protecting sensitive patient health information is non-negotiable, making adherence to frameworks like HIPAA essential. For a look at tools that can help, you might review these seven HIPAA compliant video conferencing platforms.
CDISC: Creating a Universal Language for Data
With all this data being collected, the industry needed a way to make sure everyone was speaking the same language. The Clinical Data Interchange Standards Consortium (CDISC) provides this universal dialect. CDISC standards establish a consistent format for how clinical trial data should be collected, structured, and ultimately submitted.
Two of the most crucial CDISC models you'll encounter are:
- Study Data Tabulation Model (SDTM): This model dictates a standard structure for organizing and formatting the clinical trial data that gets sent to regulatory bodies like the FDA or EMA.
- Analysis Data Model (ADaM): This model provides a standard for building the datasets used for statistical analysis, making the whole process more transparent and easier to reproduce.
By adopting CDISC standards from the beginning, sponsors make their data "submission-ready" right out of the gate. This dramatically simplifies the review process for regulators. It’s the difference between handing someone a shoebox full of crumpled receipts and giving them a perfectly balanced ledger.
Technology and Tools That Power Modern Trials

If you're picturing clinical trial data management as stacks of paper binders and endless spreadsheets, it's time for an update. Those days are long gone. Today, a sophisticated digital toolkit is the engine behind every successful study, making the entire process faster, more accurate, and just plain smarter.
The absolute workhorse of this toolkit is the Electronic Data Capture (EDC) system. It’s the central, secure hub where site staff directly input patient data into electronic Case Report Forms (eCRFs). This simple shift away from paper has had a massive impact, slashing the errors that used to plague manual transcription.
But a modern EDC does more than just hold data. It’s an active gatekeeper. Smart, automated edit checks are built right in, flagging inconsistent entries or out-of-range values the moment they’re entered. This real-time feedback is invaluable for keeping data clean from day one.
Integrating Systems for Full Oversight
While the EDC is busy gathering clinical data, it's not working alone. For the people running the trial, the Clinical Trial Management System (CTMS) provides the big-picture view. Think of it this way: if the EDC is the factory floor where the data is produced, the CTMS is the control tower overseeing the entire operation.
A CTMS is all about logistics and administration. It keeps track of things like:
- How patient enrollment is progressing across different sites.
- Schedules and reports for monitoring visits.
- The flow of trial supplies and budget management.
- Overall project timelines and key milestones.
When you connect the EDC and CTMS, something powerful happens. Study teams get a single, unified view of both the clinical data and the trial's operational health. Everyone is working from the same playbook, ensuring the data collection process is perfectly aligned with the day-to-day management of the study.
Key Insight: The real magic isn't in any single tool, but in how they work together. Integrating these systems connects the dots between patient data and trial logistics, empowering teams to spot trends, manage risks, and make informed decisions with incredible efficiency.
Capturing the Patient Voice Directly
Another game-changing innovation has been the rise of electronic Patient-Reported Outcomes (ePRO) tools. These platforms give the power directly to patients, letting them report their symptoms, quality of life, and treatment experiences on a tablet, smartphone, or web portal. This direct line of communication cuts out the middleman, avoiding potential interpretation errors and capturing the patient’s perspective authentically.
The broader category here is electronic Clinical Outcome Assessment (eCOA), which includes ePROs as well as tools for clinicians and observers to enter data directly. Of course, with all this sensitive patient information and valuable intellectual property flowing digitally, security is paramount. That’s why modern trials rely on robust encrypted file sharing solutions to keep data safe.
The Rise of AI and Predictive Analytics
The next frontier is already here: artificial intelligence (AI) and machine learning. These aren’t just buzzwords; they’re fundamentally changing the nature of data management. Instead of just reacting to mistakes after they happen, we can now use AI to predict and prevent problems before they start.
AI algorithms can sift through enormous datasets to automatically flag anomalies, identify subtle data patterns, or even forecast which sites might have data quality issues down the road. By 2025, it's projected that AI will handle up to 50% of data-related tasks in clinical trials, potentially cutting trial costs by 15-25%. This moves us beyond simple data handling and into the realm of true clinical data science, where predictive models help us do our work better and faster. You can explore insights on the future of clinical data management to learn more about this exciting shift.
The Future of Clinical Data Management
For decades, clinical trial data management followed a predictable rhythm, centered around physical sites and periodic visits. That's changing, and fast. We're moving away from these centralized models and toward something more dynamic and built around the patient's real life. This isn't about chasing the latest tech fad; it's a fundamental shift in how we think about collecting clinical data.
The core principles—data integrity, accuracy, security—are as important as ever. But now, we're applying them in a world where data comes from everywhere, all the time.
At the heart of this evolution are Decentralized Clinical Trials (DCTs). Instead of the traditional model that forces patients to travel, often long distances, to a specific clinic, DCTs bring the trial to the patient. By using remote technologies, we can gather information directly from people as they go about their daily lives, making participation far less of a burden.
This isn't just a niche idea; it's rapidly becoming the new standard. The DCT market, which relies entirely on sophisticated data management, was valued at $9.63 billion in 2024. Projections show it more than doubling to $21.34 billion by 2030. This explosive growth signals a major industry pivot towards patient-first trial designs. You can discover more about this market forecast to see just how significant this shift is.
New Data Streams from Wearables and Sensors
The rise of DCTs has opened the floodgates to data sources we could only dream of a decade ago. We're moving far beyond the data captured during a 30-minute clinic visit. Now, we're getting a continuous stream of information from all kinds of remote tech.
This deluge of data is both a massive opportunity and a serious challenge. On one hand, the possibilities are incredible:
- Continuous Monitoring: Imagine getting 24/7 vitals from a wearable sensor instead of a single blood pressure reading at a clinic. We can see how a patient’s heart rate changes throughout the day, or track their real activity levels, painting a far richer picture of their health.
- Objective Measurements: We no longer have to rely on a patient's memory. Instead of asking, "How well did you sleep last night?" we can get objective sleep-cycle data from a smart device. Medication adherence can be tracked with smart pill bottles, providing time-stamped, undeniable data.
- Early Signal Detection: With a constant flow of data, we can use algorithms to spot faint signals of an adverse event long before it becomes a crisis.
Of course, managing this firehose of information requires a complete overhaul of our old data management playbooks. The sheer volume and speed of wearable data demand much more powerful and flexible systems for intake, cleaning, and validation.
The challenge has evolved. It’s no longer just about ensuring a site coordinator enters data correctly into an eCRF. Now, we have to validate a continuous stream of information from dozens of different devices, each with its own data format and potential for error. This requires a whole new level of technical know-how and quality control.
The Growing Role of Real-World Evidence
Another huge development is how we're using Real-World Data (RWD) to generate Real-World Evidence (RWE). RWD is simply health information collected outside the confines of a traditional trial—think electronic health records (EHRs), insurance claims, or data from patient registries. When we analyze that messy, real-world data to generate clinical insights, it becomes RWE.
RWE is now routinely used to supplement traditional trial data, giving us a more complete picture. It helps us understand how a new treatment actually performs across a broader, more diverse population and over a much longer timeframe.
For data management teams, this means learning a new skill: data harmonization. This is the art of blending the highly structured, clean data from a clinical trial with the often messy, unstructured data from the real world. The goal is to create a single, unified dataset that can be analyzed for deeper insights. It’s all part of building a more holistic, patient-centered, and evidence-driven future for medical discovery.
Frequently Asked Questions
Stepping into the world of clinical data management can feel like learning a new language. Let's break down some of the most common questions that come up for sponsors, researchers, and anyone new to the field.
What Is a Data Management Plan and Why Is It So Important?
Think of a Data Management Plan (DMP) as the master blueprint for your entire trial's data. It’s not just a document; it's the rulebook everyone agrees to follow before a single piece of data is collected. This living document lays out every detail of the data journey.
It specifies everything: how data gets into the Electronic Data Capture (EDC) system, what validation rules will automatically check it, and the exact steps for handling data queries. It even covers the final procedures for locking the database. A solid DMP is the key to ensuring everyone involved in data management in clinical trials—from the clinical site to the data team—is on the same page, which is fundamental for maintaining consistency and quality.
What Is the Difference Between a Soft Lock and a Hard Lock?
In the database world, "locking" is all about securing the data at key milestones. The terms "soft lock" and "hard lock" represent two very different stages of this process.
-
Soft Lock: This is essentially a temporary freeze. It stops most new edits, giving the team a chance to perform final quality reviews on what they believe is a clean database. The key here is that it's reversible. If a last-minute check uncovers an issue, the database can be "unlocked" to fix it.
-
Hard Lock: This is the point of no return. A hard lock is the final, irreversible action that seals the database. Once applied, no more changes can be made without a major, formal, and fully documented process. It’s the official signal that the data is finalized and ready for the statisticians to analyze.
How Are Data Discrepancies Found and Fixed?
Catching and correcting data mistakes is at the very heart of good data management. The entire process is designed to be systematic and completely traceable.
It starts with automated edit checks built right into the EDC system. These are pre-programmed rules that act as an instant line of defense, flagging data that just doesn’t make sense—like an age entered as "200" or a lab value that's biologically impossible.
When a check flags an issue, or a data manager spots something odd during a manual review, a query is created. This isn't just a casual email; it's a formal request sent directly to the clinical site staff through the system, asking for clarification. The whole conversation, from question to answer to final resolution, is logged, creating a clear audit trail. This closed-loop process ensures every single data point is verified and every correction is documented.
At PYCAD, we live and breathe the complex data handling that powers medical imaging AI. We provide the expert services needed for everything from data annotation and anonymization to model training and deployment, helping you transform raw medical data into accurate diagnostic insights. Learn how we can support your next AI project.