Introduction
In the field of medical imaging, the quality and integrity of data are essential. Whether you’re a doctor reviewing patient scans or a business providing medical imaging services, duplicates in your datasets can skew results and lead to misinterpretations. Identifying and removing these duplicate scans is crucial for ensuring accurate analysis and treatment planning.
This post introduces a simple Python-based solution to detect duplicate scans in medical imaging datasets. Whether you’re working with MRI, CT, or CBCT scans, this tool can help keep your datasets clean and reliable.
The Problem with Duplicates in Medical Imaging
Medical imaging generates vast amounts of data, and managing it effectively can be a challenge. Duplicates often sneak into datasets due to:
- Multiple scans of the same area being saved under different filenames.
- Slight variations in metadata or formats leading to the same scan being treated as different.
These issues can lead to misleading analyses, slower workflows, and even incorrect diagnoses. It’s essential to ensure that every scan in your dataset is unique and properly managed.
The Solution: A Python-Based Tool to Detect Duplicates
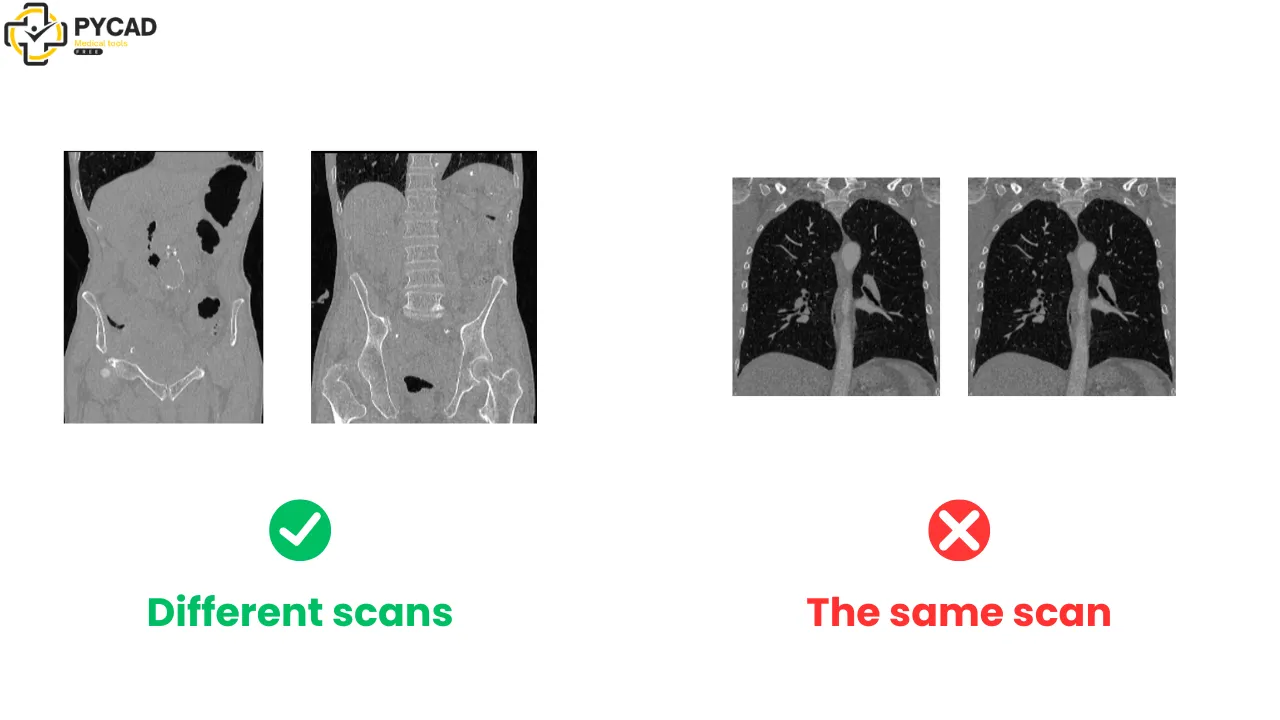
To solve this, I developed a simple Python application that automatically checks for duplicates by comparing the content of the scans, not just their filenames. This ensures that even if the files have different names or formats, the tool will detect any identical scans.
The tool works by creating a hash for each image, which serves as a unique fingerprint. Two images with the same hash are considered duplicates, even if they are saved under different filenames or formats.
How It Works
The Concept:
- Generate a unique hash for each scan based on its pixel data.
- Compare hashes to identify duplicates.
- List duplicates for easy removal or review.
Supported Formats:
This tool supports the three most common formats in medical imaging:
- DICOM
- NIfTI
- NRRD
Step-by-Step Guide to Using the App
1. Clone the Project Repository:
If you’re comfortable with coding, you can clone the project from GitHub and run it locally. Alternatively, for non-coders, we provide an easy .bat file that sets everything up with a double-click.
2. Set Up the Environment:
We’ve made it super simple to get started. Just download the repository and run the .bat file. This file will:
- Verify if Python is installed on your machine.
- Create a virtual environment.
- Install all the required dependencies.
- Launch the app for you.
No coding knowledge required!
3. Using the App:
The app provides two main functions:
- Compare Two Scans: You can manually select two scans to check if they are duplicates.
- Find Duplicates in a Folder: Select a folder containing multiple scans, and the app will automatically check for duplicates within it.

The Code Behind the App
Here’s a breakdown of how the code works. For those of you interested in the technical side, here’s the Python class that powers the duplicate detection.
import os
import hashlib
import numpy as np
import pydicom
import nibabel as nib
import nrrd
class ScanDuplicateChecker:
def __init__(self, folder_path=None):
self.folder_path = folder_path
self.supported_formats = ['.dcm', '.nii', '.nrrd', '.nhdr']
def get_image_data(self, file_path):
ext = os.path.splitext(file_path)[1].lower()
if ext == '.dcm':
ds = pydicom.dcmread(file_path)
return ds.pixel_array
elif ext == '.nii':
img = nib.load(file_path)
return img.get_fdata()
elif ext in ['.nrrd', '.nhdr']:
data, header = nrrd.read(file_path)
return data
else:
raise ValueError(f"Unsupported file format: {ext}")
def preprocess_image(self, image_data):
image_data = np.asarray(image_data, dtype=np.float32)
image_data = (image_data - np.min(image_data)) / (np.max(image_data) - np.min(image_data))
return image_data
def compute_hash(self, image_data):
preprocessed_data = self.preprocess_image(image_data)
image_bytes = preprocessed_data.tobytes()
return hashlib.sha256(image_bytes).hexdigest()
def check_duplicate(self, file1, file2):
img_data1 = self.get_image_data(file1)
img_data2 = self.get_image_data(file2)
hash1 = self.compute_hash(img_data1)
hash2 = self.compute_hash(img_data2)
return hash1 == hash2
def check_folder_for_duplicates(self):
if not self.folder_path:
raise ValueError("No folder path provided")
file_hashes = {}
duplicates = []
for root, _, files in os.walk(self.folder_path):
for file in files:
file_path = os.path.join(root, file)
ext = os.path.splitext(file_path)[1].lower()
if ext in self.supported_formats:
try:
img_data = self.get_image_data(file_path)
img_hash = self.compute_hash(img_data)
if img_hash in file_hashes:
duplicates.append((file_path, file_hashes[img_hash]))
else:
file_hashes[img_hash] = file_path
except Exception as e:
print(f"Error processing {file_path}: {e}")
return duplicates if duplicates else "No duplicates found"Why Should Doctors and Healthcare Businesses Care?
For doctors and healthcare providers, ensuring the accuracy of medical data is paramount. Duplicates in imaging datasets can lead to:
- Wasted time: Sorting through duplicate scans manually can slow down workflows.
- Potential errors: Relying on inaccurate datasets can lead to diagnostic mistakes.
By using this tool, you can automatically detect and remove duplicates, saving time and ensuring that your dataset remains clean and accurate. The process is simple and can be performed with just a few clicks, without requiring any technical expertise.
Do You Need a Custom Medical Imaging Solution?
If you’re facing challenges with your medical imaging workflow or need a tailor-made solution for managing and analyzing your imaging datasets, we’re here to help! Whether you’re a healthcare provider, clinic, or business looking for personalized software solutions, we can collaborate to build the right tools for you.
From advanced image processing and analysis to seamless integration into your existing systems, we specialize in developing custom solutions for medical imaging.
Contact us today, and let’s work together to create solutions that fit your unique needs!





