
Before you even think about algorithms or datasets, let's get one thing straight: successful AI projects are built on a solid business foundation, not just cool tech. It all starts with a clear purpose. Without that, you're just running an expensive experiment.
Building Your AI Strategy From the Ground Up
So, where do you begin? Forget the buzzwords for a moment. The real first step in any AI implementation is to ground your project in your actual business strategy. This isn't about chasing trends; it's about finding a genuine, painful problem that AI is uniquely suited to solve.
Start by looking for high-impact opportunities. For example, a manufacturing company could use AI for predictive maintenance, forecasting equipment failures to slash downtime. In e-commerce, an AI-powered personalization engine can analyze customer behavior to offer product recommendations that actually convert, directly boosting sales. The goal is to find a use case with a clear, measurable outcome.
Assess Your Organizational Readiness
Once you've zeroed in on a potential project, it's time for a reality check. You need an honest look at your organization's readiness across three critical areas:
- Data Landscape: Do you have the right data? More importantly, is it clean, relevant, and available in sufficient quantities? An AI model is only as good as the data it’s fed.
- Technical Infrastructure: Can your current systems handle the heavy lifting? AI can be computationally demanding, so you need to know if you'll need new hardware or cloud services.
- In-House Skills: Do you have the right people on board? We're talking about expertise in data science, machine learning, and software engineering.
A huge part of this is figuring out your talent strategy. You might need to explore options for hiring Data Scientists and AI/ML Engineers to fill any gaps. Taking stock like this upfront will save you a world of headaches later on.
Secure Executive Buy-In and Define Success
With a clear use case and a readiness assessment in hand, your next move is to get the executives on board. Don't frame this as a tech experiment; present it as a strategic investment. Focus on the return—whether that’s cost savings, new revenue streams, or a more efficient operation.
Your best tool for persuasion is a well-defined pilot project with crystal-clear success metrics. It's the fastest way to demonstrate tangible value and build the momentum you need for wider AI adoption.
This push for AI isn't just a niche interest anymore. It's a massive business priority. The global artificial intelligence market was valued at around $391 billion in 2025 and is only getting bigger. In fact, something like 83% of companies now see AI as a top priority in their business plans, moving it from the "maybe" pile to the core of their operations. You can dig into these AI market trends to see just how critical securing leadership support has become.
Getting this foundation right—defining the problem, assessing your readiness, and aligning with leadership—is the absolute bedrock of a successful AI rollout.
Mastering Your Data for AI Success

An AI model is only as good as the data it’s trained on. This isn't just a cliché; it's the absolute truth in medical AI. Think of your data as the foundation of a building—if it's weak or cracked, everything you build on top of it is at risk of collapse.
This is, without a doubt, the most challenging and time-consuming part of the entire process. But getting your data strategy right from the start saves you countless headaches down the line and dramatically increases your chances of success.
The first move is always to gather and consolidate your data. For a medical imaging project, this usually means pulling DICOM files from your PACS (Picture Archiving and Communication System), grabbing relevant metadata from Electronic Health Records (EHRs), and bringing it all together. The goal is to create one cohesive, accessible dataset that serves as the single source of truth for your model.
Scrubbing Your Data for Quality
Once you have all your data in one place, the real work starts. I’ve never seen a raw dataset that was ready for an AI model straight out of the box. It’s almost always messy, riddled with inconsistencies, and full of gaps that can completely derail your algorithm.
This is where data preprocessing comes in, and it's non-negotiable. You’ll find scans with missing patient metadata, wildly different image resolutions, or duplicate records from a PACS migration glitch. You have to tackle these problems methodically. This might mean tossing out low-quality or corrupted images, standardizing terms (like making sure "CT Scan" and "Computed Tomography" are treated identically), or carefully filling in missing data points using statistical methods.
A hard-learned lesson: Bad data is the number one killer of AI projects. Time spent on meticulous data cleaning is an investment that pays for itself many times over in model performance and reliability. If you rush this part, your model will fail when it meets the real world. Guaranteed.
The Art and Science of Data Annotation
With a clean dataset ready, the next step for most projects is data annotation. This is where you manually teach the AI what to look for by labeling your images. It’s how the model learns to associate specific visual patterns with a clinical outcome.
The right annotation method depends entirely on what you're trying to achieve. Here are a few real-world examples I've worked on:
- Classification: For a pneumonia detection model, you'd tag thousands of chest X-rays as simply "Pneumonia" or "No Pneumonia."
- Object Detection: To find tumors, a radiologist would draw bounding boxes around suspicious masses on a mammogram.
- Segmentation: For a project measuring organ volume, you'd need to meticulously outline the exact border of an organ, like the liver, slice by slice through a CT scan.
This is a painstaking process where precision is everything. A single misplaced pixel in a boundary around a lesion can teach the model the wrong lesson, which directly harms its diagnostic accuracy. This is exactly why your domain experts—the radiologists and clinicians—must be deeply involved. Their expertise is what turns a good dataset into a great one.
Establishing Strong Data Governance
Finally, let's talk about governance. When you're working with sensitive patient health information, building a solid data governance framework isn't just a good idea—it's an absolute legal and ethical necessity. You need clear, documented rules covering who can access the data, how it's stored securely, and how you'll maintain compliance with regulations like HIPAA.
A huge part of this is anonymization. Before any data ever touches a model, all personally identifiable information (PII) must be stripped away. This means removing names, patient IDs, specific dates, and any other identifiers from both the images and their associated records. While this can be automated, it always needs to be double-checked by a human.
By putting strong governance in place from day one, you build trust and ensure your AI work is responsible, secure, and ready for clinical application.
Picking the Right AI Model for the Job
This is where the rubber meets the road. The AI model you choose will shape your entire project—its budget, its timeline, and ultimately, whether it succeeds or fails. There’s no magic bullet here, no single "best" model for every situation. The right choice is always the one that fits your specific problem, your team's resources, and your clinical goals.
The fundamental decision often comes down to a classic dilemma: do you build a model from the ground up, adapt an existing one, or simply use a ready-made service? Each path has serious trade-offs in terms of cost, speed, and control.
This visual gives you a quick look at that initial decision point, which is heavily influenced by the kind of data you have on hand.
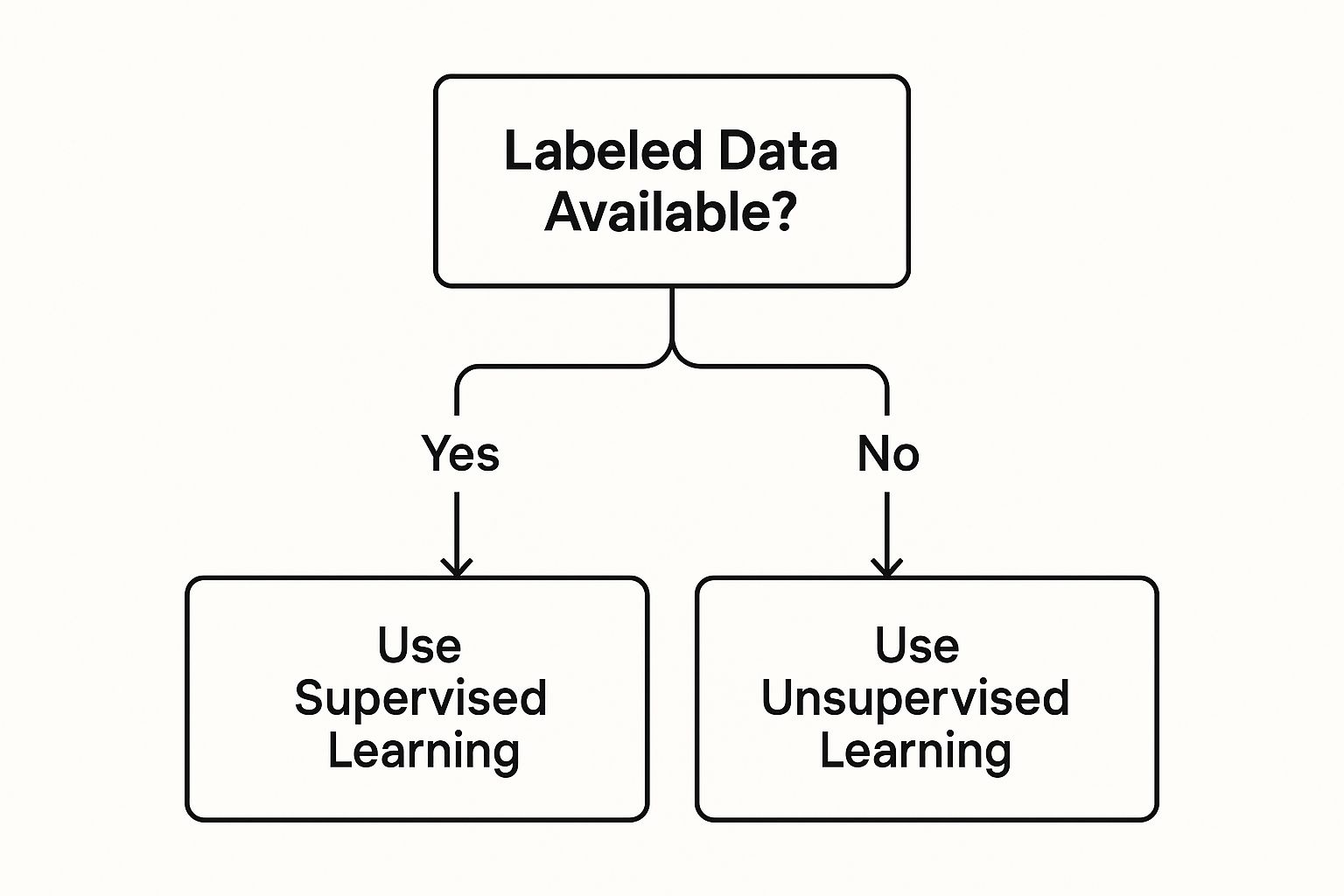
As the diagram shows, whether you have labeled data immediately sets you on a path toward supervised or unsupervised learning. Getting this first step right is foundational; it dictates your entire strategy from here on out.
AI Model Development Approaches Compared
Making the "build, buy, or adapt" decision requires a clear-eyed look at what each approach demands and delivers. I've put together this table to help you weigh the key factors based on what I've seen work (and not work) in real-world scenarios.
| Approach | Best For | Cost | Time to Deploy | Customization Level |
|---|---|---|---|---|
| Build a Custom Model | Highly specialized or novel tasks with no existing solutions. Projects with unique data and specific performance needs. | Very High | Long (months to years) | Maximum |
| Fine-Tune Pre-Trained Model | Most common medical imaging tasks (e.g., classification, segmentation). Balances performance and resource needs. | Medium | Moderate (weeks to months) | High |
| Third-Party AI Service | Standardized tasks where speed is critical and customization is not needed. Proof-of-concept projects. | Low (subscription-based) | Fast (days to weeks) | Minimal to None |
For most R&D teams and startups I've worked with, fine-tuning is the practical sweet spot. It strikes an excellent balance between high performance and manageable resource investment. Building from scratch is a massive undertaking, while third-party services often don't offer the control and data security that healthcare demands.
Selecting the Right Algorithm
Once you've settled on an approach, you have to pick the actual algorithm. This isn't about chasing the newest, most complex model. It’s about matching the tool to the task.
For example, if you're trying to predict patient readmission risk using structured data from electronic health records, a classic machine learning model like a gradient boosting machine (think XGBoost) is a fantastic, reliable choice. These models are great with tabular data and are often easier to interpret.
But for the heavy lifting in medical imaging—finding tiny patterns in a CT scan or an MRI—deep learning is the undisputed champion. A Convolutional Neural Network (CNN) is the go-to architecture for tasks like tumor detection or organ segmentation. Within the CNN family, different architectures are optimized for different jobs; a ResNet is a workhorse for classification, while a U-Net is brilliant for precise pixel-level segmentation.
My two cents: Start simple. Don't immediately reach for the most complex, state-of-the-art architecture. Kick things off with a well-established model like a ResNet-50 for a classification task. It’s a proven, robust baseline. If you can't get good results with it, something else is likely wrong in your pipeline. Get that working first, then iterate.
The Never-Ending Cycle of Training and Tuning
Training an AI model isn’t a "set it and forget it" activity. It's an iterative loop of training, checking your work, and tweaking things to squeeze out every last drop of performance. A non-negotiable part of this is splitting your data correctly.
A standard, battle-tested split looks something like this:
- Training Set (70-80%): The largest chunk of your data, used to teach the model the underlying patterns.
- Validation Set (10-15%): Used during the training process to tune model parameters and, critically, to know when to stop training before the model starts memorizing your data (a problem called overfitting).
- Test Set (10-15%): This is your final exam. It's a pristine, untouched dataset that the model has never seen before. You use it only once at the very end to get an honest report card on how it will perform in the real world.
This separation is absolutely fundamental to knowing how to implement AI responsibly. If you cheat and peek at your test set during training, your final performance metrics will be misleadingly optimistic.
During this cycle, you'll constantly be adjusting hyperparameters—things like the learning rate or batch size—based on how the model is doing on the validation set. It's a meticulous process of experimentation to find that sweet spot that gives you the most accurate and reliable model.
Putting Your AI Model to Work

A trained model collecting dust on a server is nothing more than a promising science project. The real magic happens when you get that model into the clinical workflow where it can actually start making a difference. This is the deployment phase—moving your algorithm from the clean, controlled development environment into the messy reality of a live production setting.
Choosing the right deployment strategy is a huge decision. It directly impacts your model's performance, security, and costs down the line. There’s no single "best" answer; the right choice is always rooted in your specific use case, existing infrastructure, and the regulatory hoops you need to jump through.
Choosing Your Deployment Environment
The first big question you have to answer is: where will this model actually run? Each option has its own trade-offs, so you need to be strategic and align your choice with your real-world operational needs.
You’ll generally find yourself choosing between three main paths:
- Cloud Deployment: Using platforms like AWS SageMaker, Google AI Platform, or Microsoft Azure Machine Learning gives you incredible flexibility. You can scale computing power up or down on a dime, which is ideal for handling fluctuating workloads without buying a mountain of expensive hardware.
- On-Premise Deployment: For many hospitals and clinics, data privacy is non-negotiable. If you're dealing with sensitive patient data, keeping the model on-premise is often the only way forward. It gives you total control over your data and infrastructure, but be prepared for a significant upfront investment in hardware and the ongoing costs of maintenance.
- Edge Deployment: When you need answers now, edge deployment is your best bet. This means running the model directly on or very close to the medical device itself, like an MRI machine or an ultrasound cart. It slashes latency because the data doesn’t have to make a round trip to a distant server.
A key lesson I've learned from the field is that your deployment choice isn't just a technical detail—it's a business decision. An edge deployment might offer the near-zero latency needed for a real-time ultrasound analysis tool. But a cloud solution could be far more cost-effective for batch-processing thousands of historical X-rays overnight. Always match the environment to the workflow.
Building the Bridge with APIs
Okay, so you've hosted your model. Now what? How do your existing systems, like the radiologist's PACS viewer, actually talk to it? The answer is an Application Programming Interface (API). Think of an API as a secure, standardized messenger that lets other software send data to your model and get its predictions back.
For a medical imaging AI, a typical API interaction looks something like this:
- A radiologist’s viewing software sends a DICOM image to a dedicated API endpoint.
- The API takes the image, preps it into the exact format your model needs, and hands it off to the AI.
- The model does its thing, running the analysis and generating a prediction (e.g., the probability of a specific finding).
- The API then packages this prediction into a simple, machine-readable format (like JSON) and sends it back to the viewing software.
- Finally, the software displays the result to the radiologist, maybe as an overlay or a small notification on the screen.
Building a solid, well-documented API is absolutely crucial for a smooth rollout. It’s the connective tissue that turns your AI from an isolated tool into a functional, integrated part of a larger clinical ecosystem.
Monitoring Your AI in the Wild
Deployment isn't the finish line; it’s the starting gun. Once your model is live, you have to watch it like a hawk to make sure it stays accurate and reliable. This is one of the most overlooked parts of the whole process, but it's essential for any kind of long-term success.
The world doesn't stand still, and neither does your data. A sneaky problem called model drift happens when the real-world data your model sees in production starts to look different from the data it was trained on. This could be caused by anything from the hospital buying new imaging equipment to shifts in patient demographics. Left unchecked, drift will silently kill your model's accuracy.
To catch it, you have to relentlessly track your key metrics:
- Technical Performance: Keep an eye on the basics like latency (how fast are predictions?), server uptime, and error rates.
- Model Performance: On a regular basis, re-test your model’s accuracy, precision, and recall using new, validated data to spot any performance dips.
- Data Drift: Use statistical tests to compare the incoming production data with your original training dataset. Big differences are a major red flag that it's time to investigate.
To make all of this manageable, automating your deployment and update processes is a game-changer. Adopting CI/CD pipeline best practices helps you systematically test and roll out new model versions with minimal headaches. This continuous loop of monitoring and improving is the only way to ensure your AI solution provides real, sustained value over its entire lifecycle.
Scaling AI Initiatives and Ensuring Governance

Getting your first AI project across the finish line is a huge win, but it’s really just the beginning. The next, more significant challenge is scaling that single success into a mature, organization-wide capability. This leap requires a serious commitment to governance and continuous improvement.
Scaling isn't just about churning out more models. It's about building a solid framework that lets your AI initiatives grow responsibly. Without a clear plan, you risk ending up with a collection of isolated, inconsistent, and potentially risky AI tools that don't deliver lasting value.
Establishing a Strong AI Governance Framework
As you begin to apply AI more broadly, governance becomes absolutely critical. This isn't about creating red tape; it's about putting up guardrails to manage risk, ensure ethical use, and maintain compliance. A good governance framework proactively answers the tough questions before they turn into major problems.
Think through it: Who truly owns the AI model? Who is on the hook for its performance? What's the protocol when it makes a mistake? Your framework must define these roles and responsibilities with absolute clarity. It also needs to establish a formal review process for any new AI project, scrutinizing it for potential bias, fairness, and ethical blind spots—especially when patient data is involved.
For a deep dive into building out these ethical and oversight structures, exploring AI Governance Best Practices can give you a structured approach to creating a responsible AI ecosystem. This proactive stance is what makes an organization's use of AI both effective and trustworthy.
An AI governance committee is a game-changer. By bringing together clinical, technical, legal, and ethical experts, this cross-functional team ensures every AI project aligns with organizational values and regulatory mandates long before it gets deployed.
This kind of structured oversight is a core part of learning how to implement AI in a way that can scale safely and effectively.
Creating a Continuous Improvement Loop
AI isn't a "set it and forget it" technology. The models you deploy today will inevitably degrade over time as real-world data patterns shift—a problem known as model drift. To fight this, you need a continuous improvement loop, which is the heart of MLOps (Machine Learning Operations).
This cycle is built on three core activities:
- Ongoing Monitoring: Keep a constant eye on your model's real-world performance, measuring it against the benchmarks you've established.
- Systematic Retraining: Use new, validated data from the production environment to periodically retrain your models. This keeps them sharp and adapted to the latest data trends.
- Controlled Redeployment: Have a structured process for rolling out updated models, ensuring that any improvements are thoroughly validated before going live.
This feedback loop ensures your AI solutions don't just maintain their accuracy but actually get smarter over time, delivering more and more value to your organization.
Capitalizing on Evolving AI Economics
Not long ago, scaling AI was prohibitively expensive for many. That economic landscape is changing at an incredible speed, making powerful AI more accessible than ever and opening up new opportunities for organizations of every size.
The affordability and availability of AI have improved dramatically. For example, between late 2022 and late 2024, the cost to run AI systems on par with GPT-3.5 dropped by more than 280-fold. At the same time, AI hardware costs are falling by about 30% each year, while its energy efficiency improves by roughly 40% annually. These trends mean the heavy-duty computational power needed for advanced AI is no longer just for the tech giants.
This economic shift, combined with powerful open-source tools and pre-trained models, completely changes the build-versus-buy equation. You can now experiment, iterate, and scale your AI projects far more cost-effectively, turning what used to be a massive capital investment into a manageable operational expense. By combining strong governance with a mindset of continuous improvement and taking advantage of these new economic realities, you can build a sustainable AI capability that creates a true competitive advantage.
Common Questions About AI Implementation
https://www.youtube.com/embed/cgc3dSEAel0
Even with the best plan in place, your first AI project will stir up plenty of questions. That’s perfectly normal. Getting straight, practical answers to those common sticking points is a huge part of the process. So, let’s tackle the frequent uncertainties that pop up when you're turning an AI strategy into reality.
We’ll dig into everything from figuring out your initial investment and building the right team to one of the most important topics of all: how to actually measure the return on your AI projects.
How Much Should We Budget for an AI Project?
This is always the first question, and the only honest answer is: it really depends on what you're trying to do. A simple proof-of-concept using an off-the-shelf AI service might just be a small subscription fee. A full-blown custom model, however, is a serious investment.
Your budget needs to cover a few critical areas:
- Data Costs: This isn't just about acquiring or storing data. The real heavy hitter is often high-quality annotation, which can be a major, and frequently underestimated, expense.
- Talent Costs: Whether you're hiring full-time data scientists or bringing in contractors, expert human oversight is a primary cost driver.
- Infrastructure Costs: You'll need to account for the raw computing power for training models (think cloud-based GPUs) and the servers required for deployment.
A smart way to start is by budgeting for a small, tightly-defined pilot project. This lets you prove the value of the idea and gives you a much clearer sense of the real-world costs before you commit to a full-scale rollout.
Do We Really Need a Full Team of Data Scientists?
Not necessarily, especially when you’re just getting started. The myth that you need an in-house team of PhDs just to get off the ground holds a lot of organizations back. Thankfully, the AI world has matured, and there are far more accessible entry points now.
Many powerful AI-as-a-Service platforms are built for skilled developers and analysts who don't have deep data science backgrounds. You can get a surprising amount done with these tools. A small, focused team—maybe a project manager, a software engineer, and a subject matter expert (like a radiologist)—can make significant headway.
My advice? Start lean. Work with the talent you have, bring in external experts or platforms where you have gaps, and only build out a larger internal team once your AI projects start to scale and show a clear return. It’s a much more agile and cost-effective approach.
What Is the Biggest Mistake to Avoid?
Without a doubt, the single biggest mistake I see is falling in love with the technology before identifying the business problem. Teams get excited about what AI can do and start playing with algorithms without a clear purpose. This almost always leads to a solution looking for a problem—an expensive and frustrating dead end.
A successful AI project always starts by pinpointing a specific, high-value challenge that AI is uniquely suited to solve. From there, you work backward to figure out the right data, talent, and technology. This problem-first mindset keeps your project grounded and focused on delivering tangible results.
How Do We Measure the ROI of an AI Project?
Measuring the return on investment (ROI) is absolutely critical for justifying the project and getting buy-in for future work. The trick is to tie your AI initiative to concrete business metrics you defined back in the strategy phase. Vague promises of "improved efficiency" won't cut it.
Instead, track specific, quantifiable key performance indicators (KPIs) before and after you go live. These might include:
- Cost Savings: Calculating the reduction in manual labor hours from automated tasks.
- Revenue Growth: Tying the AI to increased sales or faster diagnostic throughput.
- Operational Efficiency: Measuring lower report turnaround times or reduced error rates.
- Patient Metrics: Tracking decreased wait times or higher satisfaction scores.
By focusing on these numbers, you can build a powerful case that shows the clear financial and operational impact of your AI work.
This push for measurable outcomes is happening as the regulatory environment gets more complex. For instance, global AI-related legislative mentions shot up by 21.3% across 75 countries since 2023—a ninefold increase since 2016. In healthcare, the U.S. Food and Drug Administration (FDA) approved 223 AI-enabled medical devices in 2023 alone. That's a huge jump from just six in 2015, signaling that AI is moving from the lab to routine clinical practice. For a deeper dive, check out the AI Index 2025 findings.
At PYCAD, our expertise is in turning these complex questions into successful, real-world solutions. We partner with medical imaging companies through every stage, from data annotation and model training to seamless API deployment. Let's build the future of medical imaging together. Discover how PYCAD can accelerate your AI implementation.