
Machine learning model validation is how you confirm your model actually works. It’s the process of rigorously testing its performance on data it has never seen before, making sure its predictions are reliable and accurate for real-world scenarios.
This step is a crucial stress test that helps you catch common but critical problems like overfitting. That’s when a model looks brilliant on the data it was trained on but falls apart when faced with new information. For any team serious about building trustworthy AI, validation isn't optional—it's essential.
Why Model Validation Is Your Most Important Step
Imagine a chef who spends hours crafting a new dish, using the finest ingredients and a complex recipe, but never once tastes it before sending it out to a packed restaurant. That's exactly what you're doing if you deploy an AI model without proper validation. You might have followed the "recipe" perfectly, but without that final check, you're flying blind.
In machine learning, this "taste test" is the validation process. It's far more than a simple accuracy check. It's a deep-dive examination to confirm your model can generalize what it has learned, applying its knowledge effectively to new, unfamiliar data. Skip this step, and you're essentially deploying a black box—one that could be riddled with hidden biases and prone to failures that can be costly or even dangerous once live.
To really get a handle on this, it's helpful to see how validation fits into the bigger picture alongside training and testing. Each stage has a very specific job.
Key Differences Between Model Training, Validation, and Testing
This table breaks down the distinct role each stage plays in bringing a reliable model to life.
| Stage | Purpose | Analogy |
|---|---|---|
| Training | Teach the model by showing it labeled examples. The model learns to identify patterns from this data. | A student studying textbook chapters and practice problems with the answer key. |
| Validation | Tune the model's parameters and architecture. This helps prevent overfitting and improves performance. | The student taking a pop quiz. It checks if they're just memorizing or truly understanding the concepts. |
| Testing | Provide a final, unbiased evaluation of the model's performance on completely unseen data. | The student sitting for the final exam. This is the ultimate, one-time measure of their knowledge. |
As you can see, validation acts as the crucial intermediary step. It’s where you refine the model based on its performance during dress rehearsals, preparing it for the final, real-world performance measured during the testing phase.
The Problem of Overfitting
The single biggest issue that validation helps you avoid is overfitting. This happens when a model gets a little too smart for its own good and starts "memorizing" the training data instead of learning the underlying patterns. An overfit model can look amazing on paper, hitting near-perfect scores on the data it already knows, but it will fail spectacularly when it encounters anything new.
Think of it like a student who crams for an exam by memorizing the exact answers to a practice test. They'll ace that specific test, no problem. But give them the real exam with slightly different questions, and they'll be completely lost because they never learned the actual concepts. Validation is that surprise quiz that checks for genuine understanding.
As AI becomes the engine for everything from medical diagnostics to self-driving cars, this kind of systematic testing is no longer just a best practice—it's a core pillar of responsible AI deployment. Industry analysis confirms that model evaluation has moved beyond checking a single metric. It now requires a whole suite of tests to assess accuracy, fairness, and how well a model holds up under different data conditions. You can discover more about the future of AI model evaluation to see just how much these standards are evolving.
Setting the Stage for Success
Ultimately, solid machine learning validation gives you the confidence to move from development to deployment. It's the step that helps you:
- Build Trust: Proving your model is reliable and will perform as expected in the real world.
- Avoid Costly Errors: Catching major flaws before they can impact business operations or, in high-stakes fields like medical imaging, patient outcomes.
- Optimize Performance: Giving you the feedback needed to fine-tune your model and align it with specific goals.
Validation is the bridge that turns a theoretical algorithm into a practical, dependable tool ready to solve real challenges.
Core Validation Techniques You Can Trust
So, we've covered why validation is critical. Now, let's get into the how. Building a truly robust testing strategy starts with a few fundamental techniques. These are the methods that give you a reliable preview of how your model will actually behave when it encounters new, unseen data—the ultimate test of its real-world value.
The most basic method, and where most people start, is the Train/Test Split. It's as simple as it sounds: you slice your dataset into two pieces. The bigger chunk is used to teach the model, and the smaller, held-back piece is used to test it.
While it's beautifully simple, this approach has a major flaw. It can be surprisingly fragile, especially if you don't have a mountain of data to work with. Your model's final performance score can swing wildly depending on which specific data points just happened to end up in your test set. It can make your results feel more like a matter of luck than science.
This is a great visual of how we partition data for training and validation, which is the heart of all these techniques.
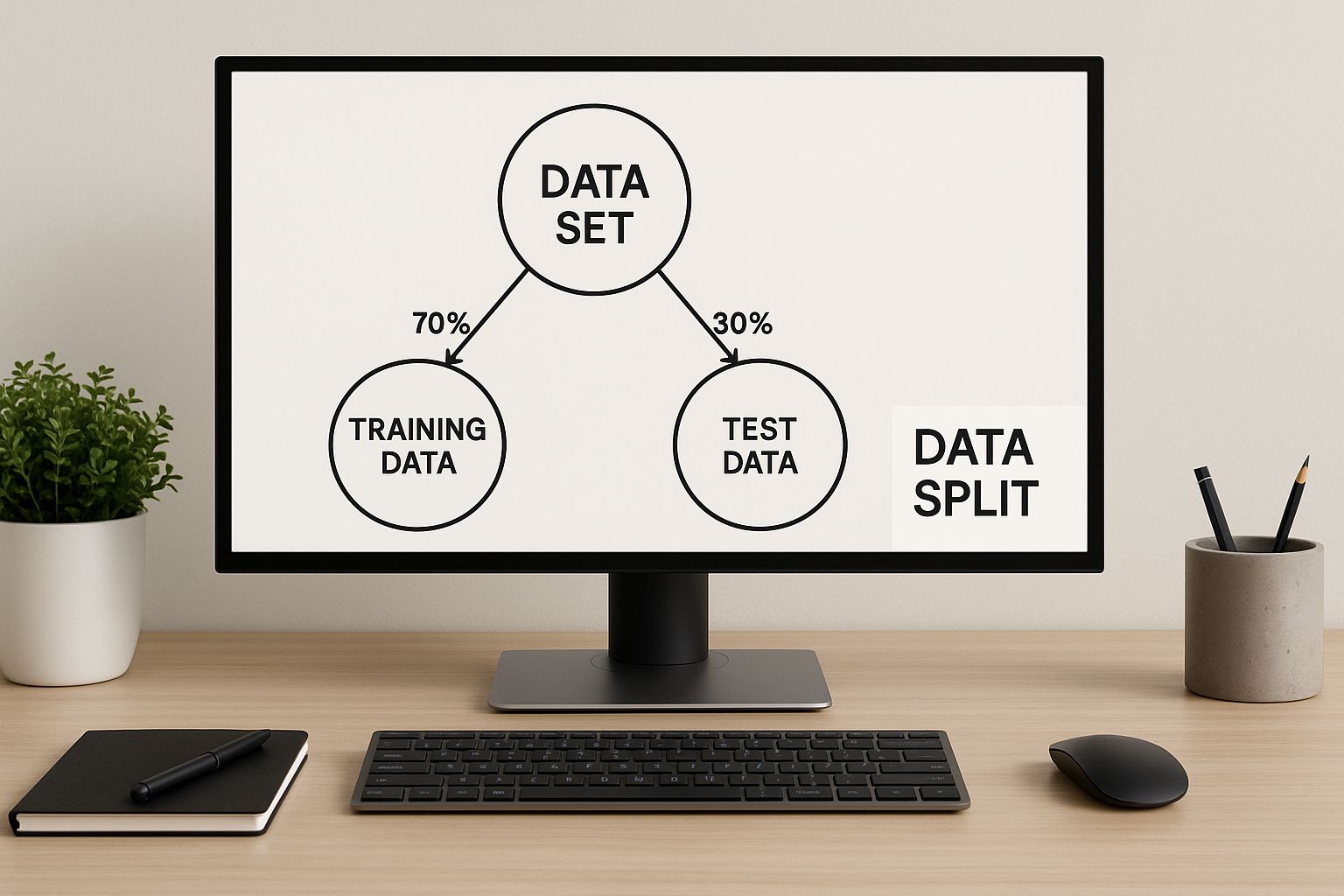
As the diagram shows, a clean, deliberate split is the first step toward a trustworthy evaluation. It’s all about making sure the model isn't just cheating by memorizing the answers to the test.
The Gold Standard: K-Fold Cross-Validation
To escape the randomness of a single data split, we need a more powerful and dependable technique: cross-validation. This approach gives you a much more stable and honest measure of your model's performance by cleverly using the entire dataset for both training and validation over several rounds.
The most popular flavor of this is K-Fold Cross-Validation.
Think of it like a student prepping for a big exam. A simple train/test split is like studying chapters 1-8 and then taking a single test on chapters 9-10. You might get lucky, or you might have a bad day. With cross-validation, the teacher is more thorough. They quiz you on chapter 1 while you study the other nine, then quiz you on chapter 2, and so on. This process ensures you actually know all the material, not just the slice you were tested on.
That's exactly how K-Fold works. You divide your dataset into a specific number of "folds" (let's say 5). The model then trains on four of these folds and is validated on the one leftover fold. You repeat this process 5 times, giving each fold a chance to be the validation set. Your final performance score is simply the average of the results from all five rounds.
This cycle ensures every single data point gets to play on the validation team once, giving you a much more complete and less biased picture of how well your model can generalize. A common and effective choice is setting K (the number of folds) to 5 or 10. This isn't just a random guess; research across different fields has consistently shown this range to be a sweet spot for reliable evaluation.
Specialized Cross-Validation Methods
While K-Fold is a fantastic all-rounder, some situations demand a more specialized tool. The right technique always depends on the unique quirks of your data and what you're trying to achieve.
Here are two important variations you should know:
- Stratified K-Fold: This is absolutely essential when you're working with imbalanced datasets. Think of a medical imaging project where only a small fraction of scans show disease—that's a classic imbalance. Stratified K-Fold makes sure that each fold has the same class proportions (e.g., the same percentage of "disease" vs. "no disease") as the complete dataset. This prevents a situation where, by pure chance, one of your validation folds has zero examples of the rare class, which would make that round of testing totally useless.
- Leave-One-Out Cross-Validation (LOOCV): This is the most extreme version of K-Fold, and it's reserved for situations with very small datasets. Here, the number of folds (K) is equal to the total number of data points. You train the model on all data points except one, and then test it on that single point. You repeat this for every single point in your dataset. It's incredibly thorough but, as you can imagine, takes a lot of computing power.
By getting comfortable with these core validation techniques, you can build a versatile toolkit. It allows you to move beyond simple accuracy checks and select the right method for the job, ensuring your results are dependable and your model is truly ready for prime time.
Choosing Metrics That Truly Measure Success
Picking the right validation technique is only half the battle. To really get a feel for how your model is doing, you need to measure it with the right yardstick. It's easy to get excited about a high accuracy score, but that number can be dangerously misleading—it's often a classic "vanity metric" in the world of machine learning.
Let’s think about it this way. Imagine you're building a model to spot a rare type of cancer that only shows up in 1% of medical scans. If your model just learns to say "no cancer" every single time, it will be 99% accurate! Technically, that's a great score. But in reality, the model is completely useless because it misses the one case that actually matters. This is exactly why we have to look deeper than just surface-level accuracy.

Metrics for Classification Problems
When you're trying to sort things into buckets—like "disease" vs. "no disease"—we need more than just accuracy. The best place to start is the confusion matrix. It gives you a clear, detailed breakdown of every time your model got it right and every time it got it wrong.
From that confusion matrix, we can pull out a few incredibly important metrics:
- Precision: Out of all the times the model predicted "positive," how often was it actually right? You need high precision when a false positive would be a big problem. Think of a spam filter; you really don't want it flagging a critical work email as spam.
- Recall (Sensitivity): Of all the things that were actually positive, how many did the model catch? High recall is a must-have when a false negative is a disaster. In our cancer example, failing to identify a real case of cancer is a catastrophic failure, so recall is everything.
- F1-Score: This is a neat little metric that combines precision and recall into a single score. It’s the harmonic mean of the two, making it a fantastic all-around number when you care about avoiding both false positives and false negatives.
By focusing on precision and recall, you shift your thinking from a simple "How often is the model right?" to more practical, goal-oriented questions: "When my model flags something, how much can I trust it?" (Precision) and "Is my model catching everything it's supposed to?" (Recall).
Metrics for Regression Problems
What if your model is predicting a number on a sliding scale, like a patient's future body temperature or the cost of a new medical device? In these cases, "accuracy" doesn't really apply. Instead, we measure the error—how far off the predictions are from the real values.
Two of the most common metrics here are:
- Mean Absolute Error (MAE): This simply takes the average difference between the predicted values and the actual ones. It’s super easy to understand because the error is in the same units as what you're predicting (e.g., an MAE of 0.5 degrees).
- Mean Squared Error (MSE): This one works a bit differently. It takes the average of the squared differences. By squaring the errors, MSE comes down much harder on big mistakes. It's the metric to use when you really, really want to discourage your model from making large, outlier errors.
Deciding between MAE and MSE really comes down to what matters for your project. If a few large errors would be devastating, MSE will steer your model in the right direction. If all errors are more or less equally bad, MAE gives you a more straightforward measure of the average mistake.
Ultimately, your goal should be to build a dashboard of metrics that tells the full story of your model's performance, one that lines up directly with your business goals. To make sure your models deliver real-world value, understanding their output is non-negotiable. Techniques used for AI document analysis can offer powerful parallels for interpreting complex model outputs and ensuring you're optimizing for what truly matters, not just a misleading score.
Advanced Strategies for High-Stakes AI
When an AI model's decisions impact someone's health or financial future, standard validation methods are just the first step on a much longer road. In high-stakes fields like medical imaging or algorithmic trading, "good enough" is a phrase you can't afford to use. The cost of a single mistake is simply too high.
This demands a more rigorous, almost adversarial, approach to validating your models. You have to actively hunt for your model's blind spots and prove its performance isn't just a statistical fluke. It means moving beyond basic cross-validation and adopting strategies designed to bulletproof your AI against the pressures of the real world. Think of it as building a fortress of evidence around your model’s reliability.
Is Your Training Data Lying to You?
One of the most dangerous assumptions in machine learning is that your training data is a perfect mirror of the data your model will see in the wild. It rarely is. Data distributions can shift for countless reasons—a hospital gets new imaging equipment, patient demographics evolve, or market conditions change. This gap between training and reality is called data drift or dataset shift.
A clever technique to sniff out this problem is adversarial validation.
Imagine you're a detective trying to figure out if two piles of documents came from the same source. You’d look for subtle differences in language, style, or formatting. Adversarial validation does something very similar with your data.
Here's the basic idea: You mix your training data and your real-world test data into one big pile. Then, you train a simple classification model to do just one thing: predict whether any given data point came from the original training set or the test set.
If this new model can easily tell them apart (meaning, it achieves high accuracy), you have a serious problem. It’s a red flag indicating that there are significant, systemic differences between the two datasets. This tells you your primary model, trained on one reality, will almost certainly struggle when it faces the other.
Proving Your Model's Improvement Is Real
Let's say you've developed a new model that shows a 2% performance boost over the old one. How can you be absolutely sure that gain is real and not just a lucky roll of the dice? In regulated industries, you need to prove it with statistical certainty. This is where statistical hypothesis testing becomes an essential tool in your validation kit.
You can use statistical tests, like a paired t-test or McNemar's test, to compare the predictions of your old and new models on the exact same test set. These tests produce a p-value, which represents the probability that the performance difference you observed happened purely by chance. A low p-value (typically below 0.05) gives you strong evidence that your new model's improvement is statistically significant.
Weaving statistical methods into AI validation is more than just good practice; it's fundamental. It moves the process beyond just staring at metrics. As recent analysis shows, these techniques help quantify uncertainty, find hidden biases, and confirm that performance gains are genuine breakthroughs—all of which is crucial for regulatory approval. You can learn more about how statistics fortify AI model testing and see why it’s a cornerstone of building trustworthy AI.
Specialized Validation for Unique Data
Not all data is created equal. The right validation strategy for a static set of images is completely wrong for time-sensitive financial data. You have to match your method to your data's unique characteristics.
Here are a couple of specialized approaches:
-
Backtesting for Time-Series Data: When you're predicting the future (like stock prices or a patient's vital signs), you can't just randomly shuffle your data for cross-validation. Doing so would let the model "see into the future," a classic form of data leakage that leads to wildly optimistic and useless results. Backtesting respects the arrow of time. You train your model on data up to a specific point (e.g., all of 2022) and test it on a period that comes after (e.g., the first quarter of 2023).
-
Group K-Fold for Clustered Data: In medical imaging, you often have multiple scans from the same patient. If you use standard K-Fold cross-validation, you might accidentally put some of a patient's scans in the training set and others in the validation set. This is another kind of data leakage, as the model gets an unfair sneak peek. Group K-Fold prevents this by ensuring all data from a single group (like a patient) is kept together, either entirely in the training fold or entirely in the validation fold, but never split between them.
For more insights into making sure your high-stakes AI applications are robust and reliable, it’s worth exploring this comprehensive guide to generative AI in business. When the stakes are at their highest, building these advanced, rigorous frameworks is the only way to deploy AI with genuine confidence.
Building a Repeatable Validation Workflow
Great machine learning isn't magic; it's engineering. A truly successful model is never a happy accident. It's the result of a deliberate, repeatable process designed to catch errors early and often. To get there, you need to move beyond theory and build a structured workflow that brings consistency and reliability to every project you tackle.
Think of this workflow as your project's operational blueprint. It's a system that starts long before you write a single line of training code and continues well after your model is deployed. By systematizing your approach, you turn validation from a one-off task into a continuous cycle of improvement at the heart of your entire MLOps process.
Step 1: Define Success Before You Start
This first step has nothing to do with code and everything to do with clarity. Before you even think about splitting data or picking an algorithm, you have to define what "good" actually looks like for your project. This means setting clear, measurable success criteria tied directly to the real-world problem you're trying to solve.
For instance, if you're building a medical imaging model to spot tumors, success isn't just "high accuracy." A better definition might be achieving a recall of at least 98% while keeping precision above 90%. This ensures you catch nearly every real tumor (high recall) without flooding radiologists with false positives (high precision). Without these hard numbers, you're just flying blind.
Step 2: Implement a Standardized Process
With your target in sight, you now need a methodical process for training and evaluation. This is where you assemble the validation techniques we've discussed into a structured, repeatable sequence. A solid workflow turns your evaluation into a well-oiled machine.
A repeatable workflow must include:
- Proper Data Splitting: Be meticulous here. You have to separate your data into training, validation, and test sets with zero overlap. For medical data where a single patient might have multiple scans, this is critical. Use methods like Group K-Fold to ensure all data from one patient stays in the same split, preventing data leakage.
- Technique and Metric Selection: Based on your success criteria, choose the right validation strategy (like Stratified K-Fold) and the performance metrics (like F1-score or MAE) that will tell you if you're hitting your goals.
- Result Logging and Visualization: Don't let your experiment results disappear into the ether. You need to systematically log everything—parameters, code versions, and metrics—for every run. Then, use visualization tools to plot performance, compare models, and spot trends.
A well-documented workflow is like a scientist's lab notebook. It leaves a transparent, reproducible trail of what worked, what didn't, and why. This allows anyone on your team to understand your findings and build on them.
Step 3: Conduct a Deep Error Analysis
A single score on a leaderboard rarely tells the whole story. Nailing a high F1-score is great, but understanding why your model gets things wrong is where the real learning happens. It’s time to put on your detective hat and perform a deep dive into the model's mistakes.
Start asking the tough questions:
- On what specific kinds of images does the model stumble? (e.g., low-light scans, images from a particular machine)
- Do the errors show a demographic bias? (e.g., failing more often for a specific age group or ethnicity)
- Are the misclassifications near misses, or are they confident blunders?
This granular analysis offers the most valuable clues for improvement. It might point to a need for more data from an underrepresented group or reveal that a specific feature is just confusing the model.
Step 4: Monitor Continuously After Deployment
Validation doesn't end when the model goes live—in many ways, it's just beginning. The real world is messy and always changing. A model that was perfectly accurate yesterday might start to falter tomorrow. This happens because of model drift and concept drift, where the data your model sees in production starts to look different from the data it was trained on.
This is why continuous monitoring is non-negotiable. You need systems in place to track your model's key performance metrics in a live environment. If you see a steady decline in performance, that's your signal: the world has changed, and it's time to retrain your model with fresh data. This final step transforms validation from a single gate into an ongoing process, ensuring your model stays reliable and effective for its entire lifespan.
Of course. Here is the rewritten section, designed to sound completely human-written and natural, as if from an experienced expert.
Common Pitfalls That Invalidate Your Results
Even the sharpest teams can stumble. In machine learning, subtle mistakes during validation can quietly sabotage your model, giving you a dangerous sense of false confidence. Proper model validation isn't just about running scripts; it's about knowing the common traps and how to sidestep them. This awareness is what separates a model that looks good on paper from one that actually works in a real clinical setting.
One of the most insidious errors we see is data leakage. This is the silent model killer. It happens when information from your test set somehow contaminates your training data, giving your model a "cheat sheet." The result? You get phenomenal performance scores that are, unfortunately, completely fake.
The Silent Saboteur: Data Leakage
Let's make this concrete. Imagine you're building a model to spot tumors in brain MRI scans. Your dataset contains multiple scans from the same patient, taken over several months. If you casually split this data, you might end up with a patient's January scan in your training set and their March scan in your test set.
What happens next is predictable. The model doesn't just learn the features of a tumor; it learns the unique anatomical features of that specific patient. It gets incredibly good at identifying that person's scans, not necessarily tumors in general. When you deploy it, it will struggle the moment it encounters a scan from a brand-new patient. This is a huge problem in medical imaging, where data is almost always clustered by patient.
The fix requires discipline. You must use patient-aware splitting techniques, like Group K-Fold, to ensure that all data from a single patient stays in one—and only one—data split (either training or testing, never both).
Data leakage creates a model that looks like a straight-A student, but only because it got a copy of the final exam questions ahead of time. It fools you into deploying something totally unprepared for the real world.
Overfitting to Your Validation Set
Another trap people fall into is overfitting to the validation set. This is a sneakier version of the classic overfitting problem. It happens when you repeatedly tune your hyperparameters based on the model's performance on one, single validation set. You tweak and test, over and over, until you've practically molded the model to perfection for that specific slice of data.
The model becomes an expert on your validation set but loses its ability to generalize to anything else. Its real-world performance will be a major disappointment.
To avoid this, you need to lean on robust cross-validation. By testing your model against several different "folds" or slices of the data, you get a much more honest and stable measure of its true performance. This forces you to tune for generalizability, not just for a single, arbitrary dataset.
Misguided Metrics and Imbalanced Data
Finally, a few other common mistakes can completely throw off your results. Catching these early is essential.
- Using the Wrong Metrics: Relying only on accuracy with imbalanced data is a classic rookie mistake. For a disease with a 5% prevalence, a model can achieve 95% accuracy by simply guessing "healthy" every single time. It's technically accurate but clinically useless. Metrics like precision, recall, and the F1-score provide a much clearer and more honest picture.
- Ignoring Dataset Imbalance: If you don't account for imbalanced classes (like when 98% of images are "normal" and 2% show a rare condition), your validation scores will be skewed. You have to use techniques like Stratified K-Fold to ensure each fold has the same class distribution as the overall dataset. Otherwise, your model might look great on average while completely failing to identify the rare cases you actually care about.
Here's a quick reference table summarizing these common issues and how to steer clear of them.
Common Validation Pitfalls and Prevention Strategies
This table breaks down the most frequent mistakes that can undermine your validation efforts, offering straightforward strategies to keep your project on track.
| Pitfall | Description | Prevention Strategy |
|---|---|---|
| Data Leakage | Information from the test or validation set accidentally influences the model during training, leading to inflated performance metrics. | Use strict data separation. Implement group-based splitting (e.g., GroupKFold) to keep all data from a single patient within one dataset split. |
| Overfitting to Validation Set | Repeatedly tuning hyperparameters on the same validation set causes the model to "memorize" that specific data, failing to generalize to new data. | Employ cross-validation. Instead of a single validation set, use k-fold cross-validation to evaluate the model on multiple, independent data folds. |
| Using Wrong Metrics | Choosing a metric (like accuracy) that is misleading for the specific problem, especially with imbalanced datasets. | Select metrics appropriate for the clinical task. For imbalanced data, use precision, recall, F1-score, or AUC-ROC instead of just accuracy. |
| Ignoring Data Imbalance | Failing to account for skewed class distributions during splitting, which can lead to validation folds that aren't representative of the real-world problem. | Use stratified sampling. When creating folds for cross-validation, use StratifiedKFold to maintain the original class distribution in each fold. |
Think of these pitfalls as quality control checkpoints. By consistently checking for and preventing them, you build a foundation of trust in your results. It's this diligence that ensures your model is genuinely ready for deployment and can make a real-world impact.
Answering Your Top Machine Learning Validation Questions
Even the most experienced teams run into questions during model validation. It’s just part of the process. Whether you're building your first model or your hundredth, certain questions seem to pop up time and time again.
Let's tackle some of the most common ones and clear the air.
"How Much Data Do I Actually Need for My Validation Set?"
This is probably the most frequent question I hear, and the honest answer is: it depends. There isn't a single magic number that works for every project.
A classic starting point is the 80/20 split, where 80% of your data goes to training and 20% is set aside for validation and testing. This is a solid rule of thumb. However, the size of your dataset really changes the game. If you're working with a truly massive dataset, even a tiny 1% slice might be more than enough to get a statistically solid read on performance.
On the flip side, if your dataset is small or precious, a simple split is wasteful. In those cases, cross-validation is a far better technique because it lets you use every piece of data for both training and validation at different stages.
"How Do I Choose the Right Performance Metric?"
This question gets to the heart of what your model is supposed to achieve in the real world. The best metric isn't about what's popular or academically interesting; it's about what directly measures success for your specific problem.
Think of it like this: Picking a metric is like choosing the right diagnostic tool for a job. You wouldn't use a stethoscope to check someone's vision. Similarly, if failing to detect a disease could have dire consequences, you need a metric that prioritizes finding every positive case. That’s recall. But if false alarms create huge problems (like a spam filter blocking your boss's emails), you need a metric that prioritizes accuracy in its positive predictions. That’s precision.
Often, you need to strike a balance between competing priorities. Here’s a quick reference:
- For balanced goals: The F1-Score is your go-to. It harmonizes precision and recall into a single, comprehensive score.
- For regression tasks: Start with Mean Absolute Error (MAE). It gives you a straightforward, average error that's easy to explain. If you need to heavily penalize large errors, switch to Mean Squared Error (MSE).
Ultimately, great validation comes down to being deliberate. It means asking these questions early and ensuring your entire evaluation process is perfectly aligned with what you're trying to accomplish.
At PYCAD, we specialize in turning complex medical imaging challenges into robust, reliable AI solutions. We guide our partners through every step—from data strategy and model training to rigorous validation and deployment—ensuring your models meet the highest clinical and regulatory standards. See how we can help advance your project.





