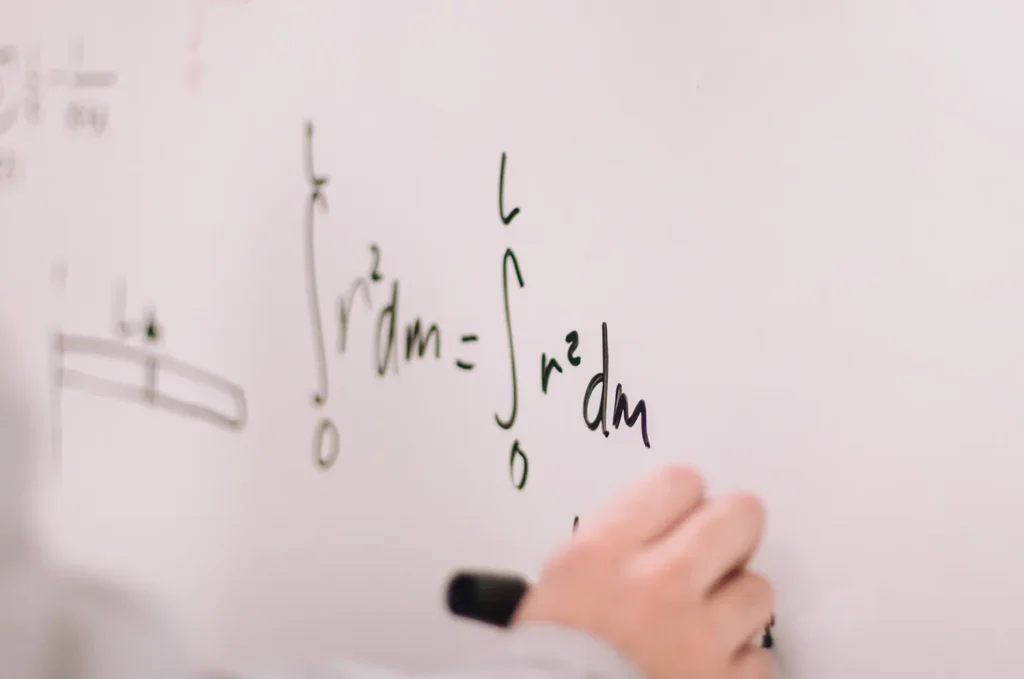
When doing image segmentation using CNNs, we often hear about the Dice coefficient, and sometimes we see the term dice loss. A lot of us get confused between these two metrics.
Physically they are the same, but when we look at their values we find that they are not the same!
The answer is very easy, but before talking about the difference between them, let’s talk about what is the dice coefficient because the dice loss is a special case of the dice coefficient.
Dice coefficient
When we do semantic segmentation for example, we want to evaluate the model either during the training which means in the validation steps or after the training which means in the testing steps. We need always to calculate a metric which is an equation between the ground truth and the predicted mask. And by looking at the values of these metrics we can say that the model is learning well or not. So the equation of the dice coefficient which can be used as a metric is two times the intersection between the ground truth and the predicted mask, divided by the sum of the ground truth and the predicted mask.

Let’s make it more clear:

The circle A is for the predicted mask and the circle B is for the ground truth.
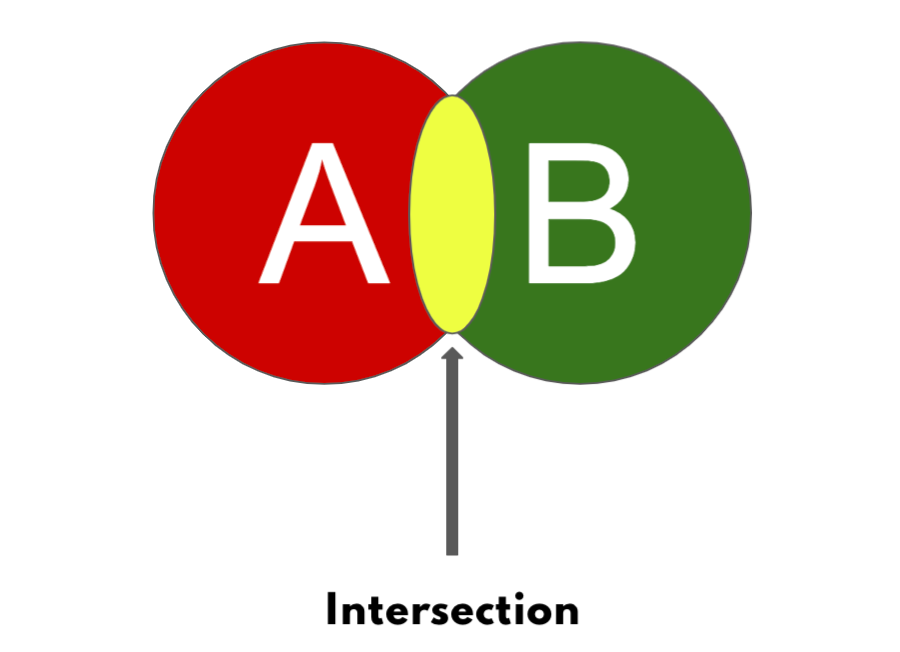
And you can see this yellow part is the intersection between the ground truth and the predicted mask.

This will be the dice coefficient, so we can see that more the intersection will go up means that the dice value will increase as well.
The minimum value that the dice can take is 0, which is when there is no intersection between the predicted mask and the ground truth. This will give the value 0 to the numerator and of course 0 divided by anything will give 0.
The maximum value that the dice can take is 1, which means the prediction is 99% correct. For that we will have the intersection equal to A or B (the prediction mask or the ground truth) because they are the same. And when multiplying them by 2 means that we will get 2 times the same value divided by 2 times the same value and the result will be 1. Let me show you this in a graph.
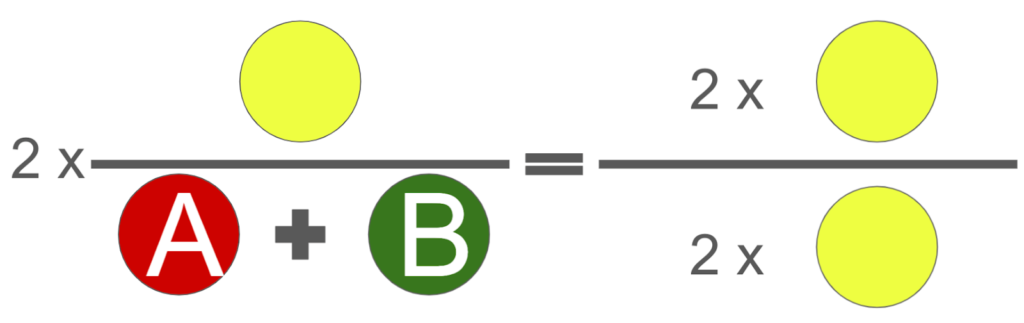
I hope that you understood the principle of the dice coefficient. From this we can know that the dice coefficient will have a value between 0 and 1, more we are near to 1 means that the model is predicting good results.
The dice loss
Now after that you understand the meaning of the Dice coefficient, the dice loss is very easy also. You remember that we said that the best values of the dice are the values that are near to 1, and we know that for the loss values we need small values which will be used to correct the weights in the backpropagation.
So we can do a small equation using the Dice coefficient to get small values instead of values near to 1.
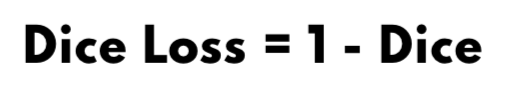
By looking at this equation, we can conclude that when the dice value will go up then the dice loss will go down, and when we get the max value of the dice then we will get 0 in the loss which means that the model is perfect (probably).
Keep Reading
Related Articles
Explore the full Segmentation HubAll services, tools, and guides on this topic — in one place.
Visit Hub →