At its core, deep learning segmentation is the process of assigning a category label to every single pixel in an image. Think of it like a hyper-detailed coloring book. A computer isn't just identifying objects; it's meticulously coloring inside the lines of a complex picture with perfect precision.
This allows the machine to understand not just what is in an image, but exactly where it is, right down to its precise boundaries.
Beyond Bounding Boxes: How Segmentation Works
To really get what makes segmentation special, it helps to compare it to other computer vision tasks. For instance, image classification might tell you, "this is a picture of a cat." Object detection takes it a step further by drawing a box around the cat.
Segmentation, however, goes much deeper. It meticulously outlines the cat's exact silhouette, pixel by pixel, cleanly separating it from the background and everything else in the scene. To really dig into these differences, it’s helpful to have a solid grasp of the fundamentals of computer vision, which is the foundational field for this kind of work.
This pixel-level understanding has completely changed the game. It allows for automated, high-resolution partitioning of images into meaningful areas. This leap forward is powered by deep neural networks, which can learn complex features straight from the image data itself, sidestepping the clunky and limited manual feature engineering that held back older methods.
The Three Core Types of Segmentation
Not all segmentation is created equal. Different types answer different questions about an image's content, and picking the right one is key to solving your problem effectively.
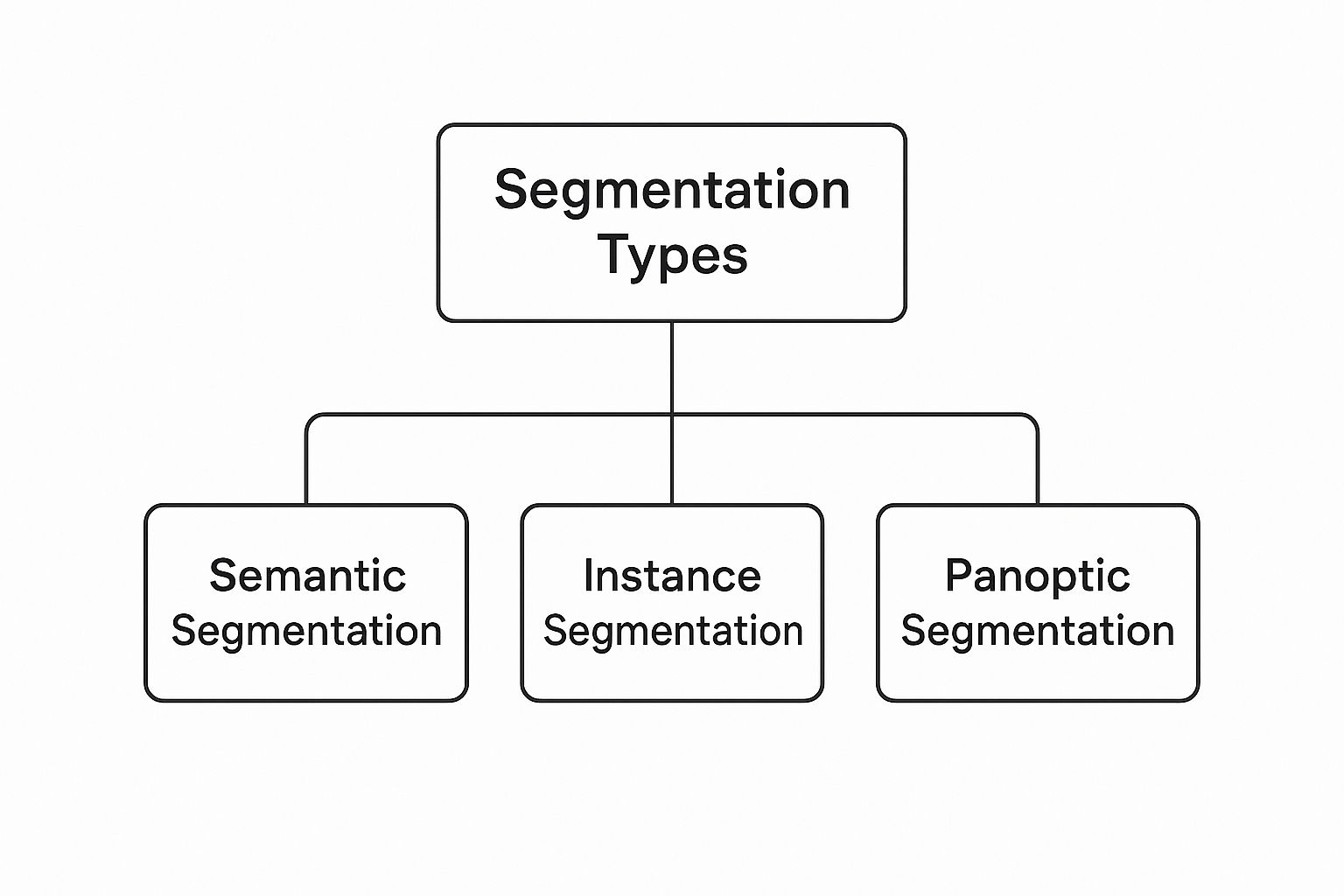
As you can see, the core idea of segmentation splits into three distinct approaches, each offering a different level of detail. Let's break them down.
-
Semantic Segmentation: This is the most common form. Its goal is simple: group pixels into broad categories. In a street scene, it would label all pixels that make up cars as "car," all pedestrians as "person," and all trees as "tree." The key here is that it cares about the category, not individual objects within that category.
-
Instance Segmentation: This approach adds another layer of intelligence. It doesn't just identify all "car" pixels; it also distinguishes between them. The output would be separate masks for 'car 1,' 'car 2,' and 'car 3.' This is vital when you need to count, track, or analyze individual objects.
-
Panoptic Segmentation: This is the powerhouse, combining the best of both worlds. It provides a complete, unified understanding of the scene. It performs semantic segmentation for background elements or "stuff" (like sky, road, buildings) and instance segmentation for distinct foreground "things" (like cars, people, signs). Every single pixel gets a class label and, if it's a "thing," a unique instance ID.
Types of Image Segmentation at a Glance
To make the differences even clearer, here's a quick side-by-side comparison.
| Segmentation Type | Core Task | Example Output |
|---|---|---|
| Semantic | Classify every pixel into a category. | All pixels for cars are colored red, all for roads are gray. |
| Instance | Detect and segment each individual object. | Car 1 is outlined in blue, Car 2 is outlined in green. |
| Panoptic | Provide a comprehensive scene understanding. | All road pixels are gray, Car 1 is blue, and Car 2 is green. |
Ultimately, choosing the right type of segmentation depends entirely on what you're trying to achieve—whether you need a general overview, a detailed object count, or a complete picture of the entire scene.
A Look at Key Segmentation Architectures
Now that we've covered the "what" of deep learning segmentation, let's get into the "how." The real magic behind creating those pixel-perfect masks happens inside specialized neural network designs, or what we call architectures. Think of these as the blueprints that tell an AI model exactly how to process an image and produce a detailed segmentation map.
The whole journey into modern segmentation really kicked off with a model called the Fully Convolutional Network (FCN). Before FCNs came along, most image recognition models would end with layers that flattened all the spatial information into a single prediction—like "cat" or "dog." FCNs changed the game by swapping those final layers with convolutional ones. This simple but brilliant move allowed the network to output a heatmap of predictions for every pixel, not just one label for the whole image.
This was a massive leap forward. For the first time, we had a deep learning model that could take any size image and produce a corresponding segmentation map from end to end. The early FCNs weren't perfect—their outputs could be a bit coarse and blocky—but they laid the critical foundation for everything that came after.
The U-Net Architecture: A Biomedical Breakthrough
Building on the ideas from FCN, one particular architecture rose to fame, especially within the world of medical imaging: U-Net. Its design is as elegant as it is effective, specifically built to capture the fine-grained details that earlier models often missed.
Just like its name suggests, the U-Net structure is shaped like the letter 'U'. It’s made of two distinct pathways:
- The Contracting Path (Encoder): This is the left side of the 'U'. It works like a typical convolutional network, progressively shrinking the image while applying filters to pull out high-level context. You can think of it as the network trying to understand what it's looking at.
- The Expanding Path (Decoder): This is the right side. It systematically takes the summarized information from the encoder and blows it back up to the original image size. Its job is to pinpoint exactly where those identified features are located, down to the pixel.
But the real stroke of genius in U-Net is its use of skip connections. These are direct bridges that link the encoder and decoder pathways at corresponding levels.
Why this matters: Skip connections give the decoder a direct line to the fine-grained spatial information from the early encoder layers. This simple trick prevents crucial details, like the precise edges of a tumor, from getting lost as the image is compressed and then expanded.
This diagram clearly shows the U-Net architecture, with its symmetrical encoder-decoder paths and the all-important skip connections bridging the two sides.

This U-shaped design masterfully blends high-level context with low-level detail, allowing it to produce incredibly accurate segmentation masks.
Mask R-CNN for Telling Objects Apart
While U-Net is a rockstar for semantic segmentation, a different approach was needed for instance segmentation—where you need to identify every single object individually. That's where Mask R-CNN comes in. It's a clever model that builds on top of a popular object detection framework.
Mask R-CNN tackles the problem in two stages. First, it acts like a standard object detector, scanning the image and proposing rectangular "bounding boxes" around anything that might be an object. This first step broadly answers the question, "What objects are in the image, and where are they?"
Then comes the second stage. For every single bounding box it proposed, the model runs a small FCN-like network just within that box. This generates a precise, pixel-level mask for the object inside. It's this two-step process that allows the model to separate "car 1" from "car 2," giving each one its own unique mask.
By combining object detection and segmentation, Mask R-CNN provides a powerful and versatile tool for picking apart complex scenes where individual objects need to be isolated. Getting to know these key architectures—FCN, U-Net, and Mask R-CNN—gives you a real appreciation for the smart engineering that drives modern image segmentation.
Training and Evaluating Your Segmentation Model
A sophisticated model architecture is a great starting point, but it's only half the battle. A model's real power comes from high-quality training and honest, rigorous evaluation.
Think of it this way: your model is a student, and your training data is its textbook. If that textbook is full of blurry images and incorrect labels, the student is never going to ace the final exam. The same goes for segmentation. The model's performance is directly tied to the quality of its training data—it learns from pixel-perfect annotated images, called masks, where every single pixel for a specific object has been carefully labeled. This is a much more demanding process than basic image classification, requiring precision down to the smallest detail.
Building a Robust Model with Data Augmentation
Even with a pristine dataset, a model might struggle to apply what it's learned to new images it has never seen before. That’s where data augmentation comes in. It’s a clever technique for artificially expanding your training set by applying random, realistic transformations to your existing images and their corresponding masks.
For segmentation, this is more than just flipping an image or adjusting its brightness. We use a variety of powerful techniques:
- Random Rotations and Scaling: This helps the model understand that an object is the same, no matter its orientation or size within the image.
- Elastic Deformations: This method involves subtly stretching and warping parts of the image. It's incredibly useful in medical imaging, as it simulates the natural variations you'd find in the shape of biological tissues.
- Color Jitter: By randomly altering brightness, contrast, and saturation, we can make the model less sensitive to different lighting conditions.
By creating a more diverse and challenging learning environment, these methods force the model to identify the true, underlying features of an object instead of just memorizing the training examples. The result is a much more resilient model that performs far better on real-world data.
Measuring Success with Key Evaluation Metrics
Once training is complete, how do you actually know if the model is any good? You need objective, quantitative ways to measure its accuracy. For segmentation, a couple of metrics have become the industry standard for judging how well a model's predictions line up with the hand-labeled "ground truth" masks.
The Core Idea: Both of these metrics answer one simple question: How well do the pixels predicted by the model overlap with the actual pixels of the object in the ground truth mask?
Let's break down the two most important ones:
-
Intersection over Union (IoU): Also known as the Jaccard Index, IoU is one of the most intuitive and popular metrics out there. It calculates a simple ratio: the area where the predicted mask and the ground truth mask overlap, divided by the total area they both cover. A perfect score is 1.0 (a perfect match), while 0.0 means there's no overlap at all.
-
Dice Coefficient: The Dice Coefficient is very similar to IoU and also measures overlap. It’s calculated as twice the area of the intersection, divided by the sum of the areas of both masks. It tends to be a bit more forgiving of small errors at the boundaries, which has made it a favorite in fields like medical imaging.
Guiding the Learning with Loss Functions
During training, the model needs a guide—something to tell it how far off its predictions are and in which direction to adjust. This guide is the loss function.
For segmentation tasks, we use specialized loss functions designed to directly push the model toward generating predictions with high overlap. One of the most effective is Dice Loss, which is derived straight from the Dice Coefficient metric. By working to minimize Dice Loss, the model is inherently trained to maximize its Dice score.
This entire process—running massive datasets through complex architectures and constantly minimizing loss—requires immense computational power. The rise of hardware accelerators like GPUs and specialized AI chips has been absolutely critical, enabling the breakthroughs we see today. If you're curious about the hardware side, you can explore more about deep learning hardware trends.
How Segmentation is Changing Medical Imaging
While the technical details of model architectures are interesting, the real story is what deep learning segmentation makes possible. And nowhere is that story more compelling than in medical imaging. This technology is fundamentally changing how doctors diagnose diseases, plan treatments, and ultimately, save lives.
Think about medical scans—MRIs, CTs, and digital pathology slides. They are packed with critical information, but they're also incredibly complex. For a human, manually outlining a tumor or measuring an organ across hundreds of image slices is a painstaking, time-consuming chore. It's tedious work that's also susceptible to human error and inconsistency.
This is where deep learning comes in. Segmentation models automate this entire process, performing the task with a speed and consistency that humans simply can't match. They turn noisy, grayscale images into structured, measurable data, empowering clinicians to make faster, more informed decisions. This isn't science fiction; it’s already happening in hospitals and research labs around the world.
A New Era in Cancer Treatment and Diagnosis
Oncology is one of the fields feeling the most significant impact. Precisely outlining tumors and nearby healthy organs is absolutely essential for effective cancer treatment, particularly for radiation therapy.
Before a patient starts radiation, an oncologist has to map out a highly detailed plan to zap the cancerous cells while protecting the surrounding healthy tissue. Drawing these boundaries on an MRI or CT scan by hand can take hours. A deep learning model can do it in minutes, sometimes even seconds.
This incredible speed-up brings a few major advantages:
- Rock-Solid Consistency: The model delivers the same precise outline every single time, eliminating the natural variations that occur between different doctors.
- Faster Treatment Planning: Slashing the time it takes to delineate structures means treatment can begin sooner, which is often crucial for fast-growing cancers.
- Pinpoint Accuracy: Automated segmentation can often detect and trace subtle tumor edges that are difficult to see by eye, leading to more targeted and effective radiation.
But it’s not just about radiation. Segmentation is also transforming pathology. When a pathologist examines a biopsy slide, they're looking for cancerous cells among millions of healthy ones. Deep learning models can scan these digital slides, segmenting different tissue types and even flagging individual cancerous nuclei. This helps pathologists work more efficiently and directs their attention to areas that need a closer look, speeding up the entire diagnostic process.
Sharpening the Surgeon's Scalpel
Surgery is another area where the detailed anatomical maps created by segmentation are invaluable. Before a major operation like a liver resection or a kidney transplant, surgeons need a crystal-clear picture of the patient’s unique anatomy.
By automatically segmenting organs, blood vessels, and other vital structures from pre-op scans, deep learning models can create patient-specific 3D models. Surgeons can then use these virtual replicas to rehearse the surgery, map out their approach, and identify potential risks before ever making an incision.
This kind of personalized surgical planning used to be a time-intensive luxury. Now, it's becoming a practical tool that makes surgery safer and more precise. The ability to see the exact relationship between a tumor and a major blood vessel, for example, is a game-changer.
Applications of Segmentation in Medical Diagnostics
Deep learning segmentation is being applied across a wide range of imaging types to solve distinct clinical problems. The table below shows just a few examples of how this technology is being put to work.
| Imaging Modality | Segmentation Task | Clinical Impact |
|---|---|---|
| MRI (Magnetic Resonance Imaging) | Delineating brain tumors, multiple sclerosis lesions, and cardiac chambers. | Enables precise monitoring of disease progression, supports surgical planning, and automates heart function analysis. |
| CT (Computed Tomography) | Outlining tumors, quantifying lung damage, and segmenting organs for radiation planning. | Accelerates cancer treatment planning, provides objective measures for lung diseases, and supports pre-surgical visualization. |
| Digital Pathology | Identifying and counting cancerous nuclei in tissue slides. | Speeds up diagnostic workflows for pathologists, reduces manual error, and helps in grading tumor aggressiveness. |
| Ultrasound | Measuring fetal biometrics and segmenting cardiac structures. | Automates routine measurements in obstetrics and provides consistent analysis of heart wall motion and blood flow. |
These applications highlight how segmentation transforms raw image data into actionable clinical insights, improving both efficiency and the quality of patient care.
The adoption of AI in healthcare is happening globally, but some regions are ahead of the curve. Currently, North America dominates the deep learning market with a 38% revenue share, thanks to its advanced healthcare systems and early embrace of technologies like medical image segmentation. You can learn more about these market trends and their drivers to see how this investment is accelerating the integration of AI into clinical workflows.
From spotting brain tumors to measuring damage in the lungs, deep learning segmentation is acting as a powerful co-pilot for medical experts. It takes on the repetitive, labor-intensive work of outlining anatomical structures, freeing up clinicians to focus their skills on what truly matters: diagnosis, treatment strategy, and patient care. The result is a more efficient, accurate, and personalized approach to medicine.
Navigating the Real-World Hurdles of Implementation
While the promise of deep learning segmentation is huge, getting a model from a research paper into a real, working system is another story entirely. It's a path filled with very practical, and often frustrating, challenges. You can have the most brilliant architecture in the world, but if you can't solve the data, bias, and resource problems, your project is dead in the water.
Successfully building a segmentation solution means anticipating these roadblocks and having a game plan. Let's dig into the three biggest headaches you'll almost certainly run into and how to actually solve them.
The Data Annotation Bottleneck
Here's the single biggest barrier to entry for most segmentation projects: getting enough high-quality, pixel-perfect training data. This isn't like classification where you just slap a "cat" or "dog" label on an image. Segmentation demands that someone—often a highly paid expert like a radiologist—meticulously draws a mask around every single object of interest, pixel by pixel.
This process is brutally slow and expensive. It’s the kind of problem that can stop a project before it even starts. Fortunately, there are ways to work smarter, not just harder, with the data you have.
- Semi-Supervised Learning: Start with a small, perfectly labeled dataset. Train a "starter" model on it, then use that model to predict masks on a much larger set of unlabeled images. You take the model's most confident predictions, treat them as "pseudo-labels," and feed them back into the training process to make the model smarter.
- Active Learning: Don't just label images at random. An active learning system has the model pinpoint which images it finds most confusing. By having your human experts focus their limited time on these tricky examples, you get a much bigger performance boost for your labeling effort.
- Weak Supervision: Instead of demanding perfect pixel masks for everything, you can get started with "weaker" labels. This could mean using simple bounding boxes or even just image-level tags (e.g., "this scan contains a tumor"). These less precise labels can help the model learn the basics before you refine it with more detailed data.
Taming Lopsided Data
Another classic problem is class imbalance. Think about trying to find a tiny tumor in a massive MRI scan. The "background" pixels might outnumber the "tumor" pixels by a ratio of 1000:1 or even more. If you're not careful, the model will quickly figure out it can achieve 99.9% accuracy by just predicting "background" for the entire image, completely ignoring the one thing you actually care about.
This makes the model completely useless. It becomes heavily biased toward the majority class and fails at its core mission.
The trick is to force the model to pay attention to the small but crucial details. Specialized loss functions, like Dice Loss or Focal Loss, are designed for this. They effectively penalize the model more for getting the rare class wrong, making it impossible for the model to ignore it during training.
You can also use oversampling techniques, which essentially means showing the model examples of the rare class more often. Both strategies help balance the scales and train a model that can reliably find those needles in the haystack.
Managing the Computational Beast
Let’s be honest: deep segmentation models are resource hogs. Architectures like U-Net and its descendants have millions of parameters and are incredibly demanding to train. They often require beefy GPUs and can run for days. Then comes deployment—trying to get that massive model to run in real-time on a doctor's tablet or an embedded device is a whole different challenge. A slow, clunky model isn't practical.
The good news is you can put your model on a diet without losing all its strength. This is where model optimization comes in.
- Model Pruning: Think of this like trimming a bonsai tree. It’s a process that intelligently snips away redundant or non-essential connections within the neural network. The end result is a much smaller and faster model.
- Quantization: This technique reduces the precision of the model's numbers, for example, by converting 32-bit floating-point values into much simpler 8-bit integers. This can dramatically shrink the model's file size and speed up calculations, making it possible to run on less powerful hardware.
By proactively tackling these three core challenges—the data bottleneck, class imbalance, and computational costs—you can bridge the gap between a promising idea and a robust, practical segmentation tool that works in the real world.
Frequently Asked Questions

Even after getting a handle on the models and metrics, a few practical questions always seem to pop up when you're in the trenches with deep learning segmentation. Let's tackle some of the most common ones I hear from practitioners.
What Is the Difference Between Semantic and Instance Segmentation?
This is probably the most fundamental question, and the answer really boils down to one thing: are you interested in the group or the individual?
Think about a photo of a busy street packed with cars.
-
Semantic segmentation lumps them all together. It paints every single pixel belonging to any car with the same color, labeling it all as 'car.' It's great for understanding the overall scene composition—what's in the picture.
-
Instance segmentation, on the other hand, gets personal. It doesn't just see 'car'; it sees 'car 1,' 'car 2,' and 'car 3,' giving each one its own unique mask.
So, semantic segmentation gives you the "what," while instance segmentation gives you the "which one." The one you choose depends entirely on whether you need to know that cars are present or if you need to track each specific vehicle.
Why Is U-Net So Popular for Medical Image Segmentation?
There's a good reason U-Net became the rockstar of medical imaging. Its architecture is almost tailor-made for the unique problems we face with biomedical data.
For starters, its skip connections are brilliant. They act like express lanes, connecting the early, high-resolution feature maps with the later, more abstract ones. This lets the model see both the forest and the trees—it can understand the high-level context (like "this is a tumor") while simultaneously using fine-grained spatial details to draw a super-precise boundary around it. That's absolutely critical for outlining organs or lesions.
The other big win is that U-Net is incredibly data-efficient. In the medical world, you can't just scrape a million images off the web. Getting thousands of expert-annotated scans is a massive, often impossible, undertaking. U-Net can learn effectively from the smaller datasets we actually have, making it a pragmatic and powerful choice where data is precious and precision is everything.
How Much Data Do I Need to Train a Segmentation Model?
This is the classic "how long is a piece of string?" question. There’s no magic number. It really depends on the complexity of your problem and the diversity of your images.
For a straightforward task—say, segmenting one or two classes under consistent lighting—you might get by with a few hundred well-annotated images, especially if you get creative with data augmentation.
But for a complex scene with tons of object classes, or images with wild variations in angle, lighting, and background clutter, you’ll likely need thousands of examples to build a robust model.
The most important thing to remember is this: quality trumps quantity. A small, meticulously labeled dataset will almost always outperform a massive, sloppy one. A good strategy is to start with a modest but high-quality dataset, train a baseline model, and then analyze its mistakes to guide you on what new data to add next.
What Are the Biggest Challenges in Deploying Segmentation Models?
Getting a model to perform well in a Jupyter Notebook is one thing. Getting it to work reliably in the real world is a completely different ballgame. The hurdles usually fall into three main buckets.
-
Performance: Many segmentation models are resource hogs. Trying to get one to run in real-time on a small device, like a camera or a portable ultrasound machine, is a huge challenge. This is where you have to get serious about optimization, using techniques like model quantization or pruning to make it faster and lighter.
-
Robustness: Your model might be a champion on your clean, curated test set, but what happens when it sees an image from a different camera, or one taken at night? A model's ability to generalize to these unseen conditions is what makes or breaks it in production. It needs to be tough.
-
Maintenance: A model is not a "set it and forget it" solution. Its performance will inevitably degrade over time as the real-world data it sees begins to drift from what it was trained on. You need a solid plan for monitoring its predictions, catching failures, and periodically retraining it with new data to keep it sharp.
At PYCAD, we specialize in solving these exact problems. From expert data annotation to optimizing complex models for deployment, we offer end-to-end AI services designed for medical imaging. If you're ready to bring powerful deep learning segmentation to your medical devices, let's work together to shape the future of healthcare. Learn more at https://pycad.co.





