
Picture this: hospitals from every corner of the world, all working together to create a brilliant AI that can spot the rarest of diseases. Now, imagine they do this without a single patient record ever leaving the hospital it came from. This isn't a scene from a sci-fi movie; it's the incredible reality of federated learning in healthcare. It's a completely new way of thinking about AI, one that trains models on data spread across different locations, sparking a revolution in medical research while fiercely protecting patient privacy.
The Dawn of Collaborative AI in Medicine
For years, AI has faced a fundamental paradox in medicine. To build truly powerful diagnostic tools, you need massive, diverse datasets. But privacy laws and our ethical duty to patients make pooling that sensitive health information a non-starter. This is the very problem federated learning was designed to overcome.
Here’s a simple way to think about it. Imagine a team of elite librarians, each responsible for a priceless collection of rare books (patient data). These books are too valuable to ever leave their respective libraries (hospitals). Instead of trying to ship all the books to one central place, a brilliant apprentice (the AI model) travels from library to library. At each stop, the apprentice learns from that unique collection, gets smarter, and then moves on, accumulating a world of knowledge without a single book ever changing hands.
Federated learning allows the AI model to travel to the data, not the other way around. This fundamental shift keeps sensitive patient information secure within hospital walls while still enabling large-scale, collaborative research.
This elegant solution means innovation and privacy are no longer at odds. They become partners. It opens up a new frontier for researchers, medical device makers, and hospital IT leaders to redefine what's possible in medicine.
Before we dive deeper, let's quickly see how this approach stacks up against the old way of doing things.
Federated Learning vs Traditional AI in Healthcare
This table paints a clear picture of the fundamental shift in how data is handled, moving from a centralized risk to a decentralized, privacy-first model.
| Aspect | Traditional Centralized AI | Federated Learning (FL) |
|---|---|---|
| Data Location | All data is collected and stored in a single, central server or cloud. | Data remains in its original location (e.g., individual hospitals). |
| Privacy Risk | High. A single breach of the central server can expose all patient data. | Low. Raw patient data never leaves its secure environment, minimizing breach risk. |
| Data Movement | Massive amounts of sensitive data must be transferred to the central location. | Only the AI model's learned parameters (not raw data) are shared and aggregated. |
| Collaboration | Difficult. Hindered by data sharing agreements, regulations, and institutional barriers. | Seamless. Institutions can collaborate without sharing their confidential patient data. |
| Regulatory Burden | Significant. Complying with regulations like HIPAA across pooled data is complex. | Simpler. Helps organizations comply with data privacy laws by keeping data local. |
In short, federated learning flips the script, bringing the intelligence to the data and leaving privacy intact.
The Driving Force Behind Medical AI
This isn't just a clever idea; it's a movement with serious momentum. The global federated learning in healthcare market is exploding, valued at USD 28.83 million and on track to grow at an impressive 16.0% each year from 2025 to 2030. This growth is being driven by the critical need for AI that respects privacy, especially in medical imaging and diagnostics. North America is leading the charge with a 34.4% market share, thanks to its top-tier healthcare systems, major investments in AI, and strong data privacy laws like HIPAA. You can explore more market research on federated learning to see just how fast this field is moving.
Here at PYCAD, we're right in the thick of it. We at PYCAD, build custom web DICOM viewers and integrate them into medical imaging web platforms—creating the perfect home for these advanced AI models. Our work is all about providing the secure, intuitive tools needed to bring federated learning out of the lab and into the real world of clinical care, turning shared insights into life-saving diagnoses. You can see examples of our integrated solutions in our portfolio.
How Collaborative AI Training Actually Works
To really get your head around federated learning, you have to look past the high-level concept and dive into how it actually works on the ground. It’s less about magic and more about a brilliantly simple, coordinated effort between a central server and multiple, independent hospitals.
Think of the central server as a project manager. It doesn't hold any sensitive patient data. Not a single scan or record. Its job is to create the initial "blueprint" for an AI model—a starting point designed for a specific task, like spotting tumors in brain scans. This blueprint gets sent out to all the participating hospitals and clinics.
The Local Learning Phase
This is where the real work begins. Once a hospital receives the model blueprint, its own local servers take over. The model is then trained on that hospital's private, internal patient data, safely behind its own firewall. This is the most important part of the entire process: all learning happens locally, meaning sensitive information never leaves the institution.
As the model trains on this local dataset, it starts picking up on the unique patterns and characteristics of that specific patient population. What comes out of this is a slightly improved version of the original model—a package of what are essentially "local learnings" or updates. It’s a summary of what was learned, not the data used for learning.
This is the core idea: insights travel, but the data stays put.
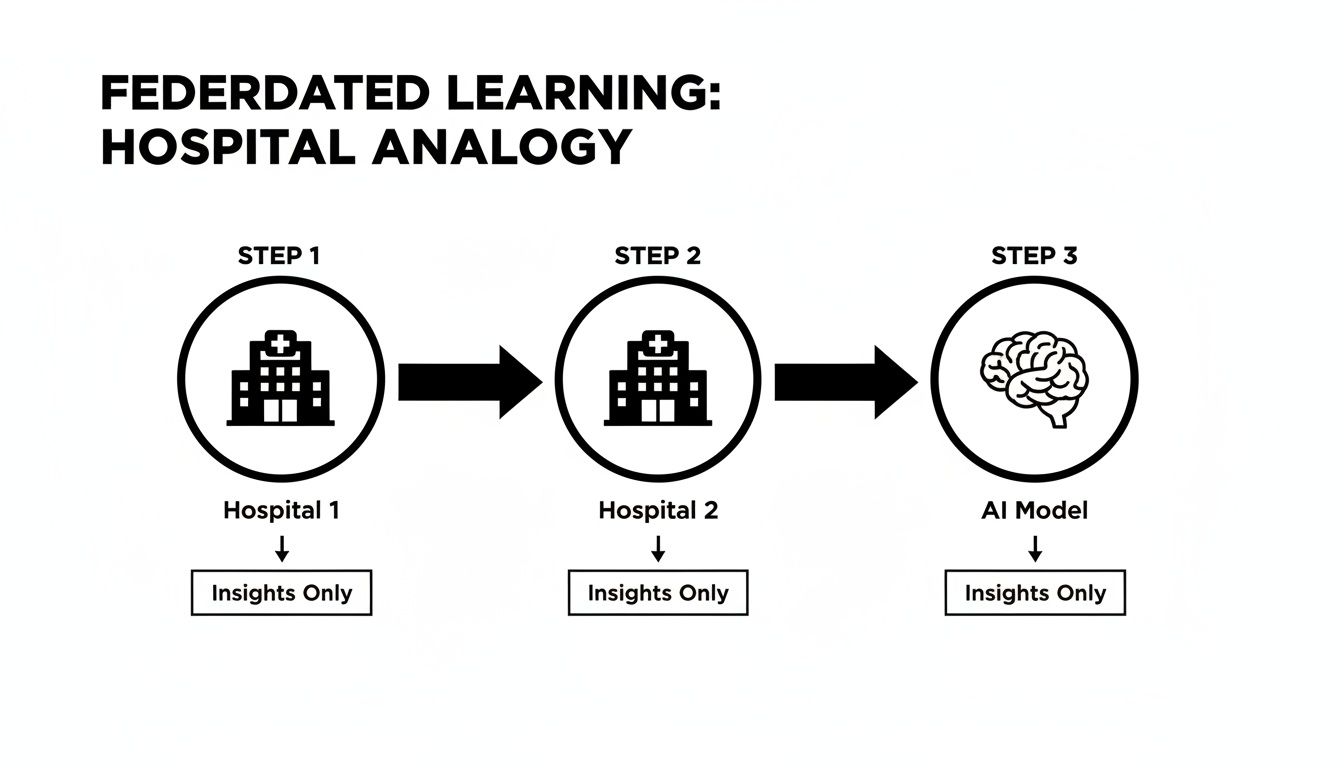
The one-way flow of anonymized knowledge is what makes this entire technique possible while respecting patient privacy.
Creating a Smarter Global Model
Now for the collaborative part. Each hospital sends only its newly trained model updates back to the central server. The raw data—the actual MRIs, CT scans, and patient notes—remains securely locked down within the hospital's system. No one else ever sees it.
The central server's next job is aggregation. It intelligently combines all the learnings sent back from every single hospital. By averaging out these updates, it pieces together a new, much smarter "global model." This new version holds the collective wisdom from incredibly diverse patient datasets spread across different locations, making it far more powerful and accurate than any single model could ever be.
Think of it as a continuous cycle. The global model is distributed, trained locally on new data, and the insights are sent back and aggregated. Each time this loop completes, the model gets progressively smarter—like a medical resident learning from a whole team of seasoned specialists.
This iterative process is the engine that drives federated learning in healthcare. If you want to dig deeper into the nuts and bolts, our guide on the fundamentals of machine learning model training is a great place to start.
This approach ensures the AI gets the benefit of massive, diverse datasets without ever compromising patient privacy. It's a secure, cyclical process that truly represents a major step forward for medicine.
Building the Future of Medical Imaging with Federated Learning
Medical imaging is where the real magic of federated learning happens. This is the world of DICOM (Digital Imaging and Communications in Medicine)—the universal format for every MRI, CT scan, and X-ray. These images hold the keys to early diagnosis and life-saving treatments, but they are also deeply personal, which rightly keeps them locked away.
Federated learning offers a way to pick that lock without ever taking anything out of the vault. It lets us train exceptionally smart diagnostic AI by learning from vast, diverse imaging datasets scattered across countless hospitals. And the most incredible part? It all happens without a single piece of patient data ever leaving an institution's firewall. Confidentiality is preserved, but collective intelligence is unleashed.
Think about a future where an algorithm can spot the faintest, earliest signs of a rare cancer. This isn't an algorithm trained on data from just one hospital. It’s one that has learned from thousands of scans in different cities and countries, each contributing a tiny piece of the puzzle. This shared learning creates models that are far more robust, accurate, and fair than anything a single institution could hope to build on its own.
The Power of Collaborative Research
The effect on collaborative medical research is profound. During the COVID-19 pandemic, for example, a landmark study united 20 global institutions to create clinical outcome prediction models using this very approach. The results were stunning: the federated models dramatically outperformed those trained on isolated, local data. This is a game-changer for every researcher and scientist working with medical images. You can dive into the specifics of this groundbreaking work and discover more insights about federated medical research.
This new model of global teamwork allows us to confront some of medicine's biggest challenges by securely pooling our collective knowledge.
By enabling AI to learn from a global tapestry of medical images without compromising privacy, federated learning is not just improving diagnostics—it is creating a new foundation for medical discovery itself.
From Theory to Clinical Reality
Turning this brilliant idea into a real-world clinical tool takes more than just a clever algorithm. It requires a secure, intuitive platform where these powerful models can be put to work. This is exactly where our team at PYCAD steps in. We don't just theorize about the potential; we build the practical infrastructure that makes it a reality for healthcare providers.
At PYCAD, we build custom web DICOM viewers and integrate them into medical imaging web platforms. Our solutions are designed from the ground up to be the perfect, secure home for deploying federated learning models right into the clinical workflow.
Here’s why our platforms are the ideal foundation for this advanced AI:
- Secure Data Handling: We build our platforms with security as the number one priority. Patient imaging data stays protected within the hospital's own ecosystem, which perfectly mirrors the core principle of federated learning.
- Seamless DICOM Integration: We are experts in handling complex DICOM data. Our custom viewers let clinicians interact with medical images naturally, while AI models run in the background, offering crucial diagnostic support.
- Clinical Workflow Enhancement: We embed these AI tools directly into the platforms clinicians already use every day. This closes the gap between an abstract AI insight and a confident clinical decision, making the technology truly useful at the point of care.
We connect the brilliant concept of federated learning to a tangible solution that helps clinicians improve patient outcomes. This integration is the key to unlocking the full power of collaborative AI in medicine. You can see how we put these ideas into practice by looking at our past projects. To see what we can build, please view our portfolio here.
Choosing Your Federated Learning Architecture
Just like hospitals have different layouts and specialties, federated learning isn't a one-size-fits-all solution. Picking the right architecture is a foundational decision that dictates how your partner institutions will work together, how insights will flow, and who's in charge of the whole operation. It's the blueprint for your collaborative AI, so getting it right from the start is absolutely crucial.
When it comes to federated learning in healthcare, you'll generally encounter three main models. Each one has its own distinct personality, with unique strengths and ideal scenarios. The best choice really hinges on your project's goals, the number of collaborators you have, and the kind of data you're working with.
The Centralized "Hub-and-Spoke" Model
The most popular and straightforward setup is the centralized, or "hub-and-spoke," model. Imagine a single, trusted central server acting as the project's air traffic controller. This server initiates the global AI model, distributes it to all participating hospitals, and then carefully gathers and averages their anonymized updates to craft a more intelligent, refined version.
This approach brings some clear wins:
- Simplicity and Control: With one orchestrator, managing, monitoring, and updating the process is incredibly straightforward.
- Efficiency: The aggregation is streamlined because all the model updates come back to one place.
- Scalability: It works beautifully for large-scale research consortiums that might involve dozens, or even hundreds, of institutions.
The flip side, of course, is that having a single server creates a potential bottleneck or a single point of failure. If that central hub goes offline, the whole learning process grinds to a halt. This model is perfect for big, organized projects where a lead institution or a neutral third party can reliably play the coordinator role.
The Decentralized Peer-to-Peer Network
Now, let's imagine a system with no central authority at all. In a decentralized architecture, every institution communicates and shares model updates directly with each other, like colleagues sitting around a collaborative roundtable. Each member shares their piece of the puzzle, and together, they build a collective understanding.
This peer-to-peer model is a fantastic fit for smaller, more nimble collaborations—say, a partnership between two specialized clinics focused on a rare disease. It’s naturally resilient because there's no single point of failure. However, it can get complicated to manage as more partners join, and achieving a consensus across a large network can be a real challenge.
Heterogeneous Federated Learning for Real-World Data
Let's be honest: healthcare data is messy. Different hospitals use different scanners, store data in different formats, and treat different patient populations. This is where Heterogeneous Federated Learning comes in. It’s a more advanced architecture built specifically to embrace this real-world complexity. It uses clever algorithms to train a single, powerful model even when the data from each partner isn't perfectly uniform.
This is what makes federated learning truly practical. It doesn't pretend that all data is clean and consistent. Instead, it accepts the messiness of healthcare and turns that diversity into a strength, creating more robust models that work in the real world.
At PYCAD, we live and breathe this stuff. We at PYCAD, build custom web DICOM viewers and integrate them into medical imaging web platforms that can support any of these architectures. Whether you need a centralized hub for a massive research network or a nimble peer-to-peer setup, our platforms deliver the secure, flexible foundation you need to succeed. To see how these ideas become clinical tools, you can learn more about how to deploy an AI model in a healthcare setting or check out our portfolio page.
In the end, choosing the right architecture gives you a clear roadmap for success, whether you're running on-premise servers tucked away in hospital data centers or coordinating everything through the cloud.
Navigating Data Privacy and Regulatory Hurdles

At its heart, the design of federated learning is a brilliant step forward for data privacy. Think of it as a powerful foundation, not an impenetrable fortress. Its core promise—keeping raw patient data safely inside its original hospital walls—perfectly matches the spirit of strict regulations like HIPAA in the United States and GDPR in Europe.
This model instantly shrinks the potential for data breaches and simplifies the tangled web of compliance. It lets hospitals join forces on incredible research without the massive legal and security headaches that come with old-school data-sharing contracts.
Beyond the Basics of Keeping Data Local
But great data stewardship means digging deeper. Even when raw data stays put, the model updates sent back to the central server can, in theory, reveal clues about the information they were trained on. A determined attacker might try a model inversion attack, a sophisticated method to reverse-engineer parts of the original training data from the model’s parameters. It's a real, if complex, risk.
That’s why a modern, secure federated learning setup never works in isolation. It’s always part of a bigger strategy, reinforced with extra layers of security to create a defense-in-depth approach for protecting patient information.
True privacy in collaborative AI isn't about one single technology. It's about a smart, layered combination of techniques. Federated learning builds the frame, and other privacy-enhancing tools are the essential reinforcements.
To forge this stronger defense, engineers bring in some advanced cryptographic and statistical tools.
- Differential Privacy: This is like adding a tiny, carefully measured bit of statistical "noise" to the model updates before they're shared. This controlled fuzziness makes it mathematically impossible to pinpoint and identify any single individual from the data, offering a provable guarantee of privacy.
- Secure Multi-Party Computation (SMPC): Picture each hospital locking its model update in a digital vault before sending it. SMPC is the magic that lets the central server combine all these locked vaults without ever opening them. The server gets the collective wisdom it needs, but never sees the individual contributions.
- Data Anonymization: Even before the training starts, applying robust data anonymization adds yet another crucial safeguard. We actually have a great resource if you want to understand the finer points of this process: https://pycad.co/what-is-data-anonymization/.
Building a Compliant and Ethical Framework
Putting these technologies into practice is about more than just checking a box for compliance; it shows a genuine commitment to ethical responsibility. For compliance officers and tech teams, the goal is to build a system that earns the trust of everyone involved—patients, doctors, and all participating hospitals.
When navigating the complex rules around federated learning in medicine, a deep understanding of patient data protection is non-negotiable. This practical guide to HIPAA compliance is a fantastic resource to build that knowledge.
At PYCAD, we live and breathe this balance. We at PYCAD, build custom web DICOM viewers and integrate them into medical imaging web platforms, weaving these advanced privacy measures directly into the architecture. Our solutions, which you can view on our portfolio page, are engineered to meet the highest data protection standards, giving healthcare pioneers the peace of mind they need to truly advance the future of medical AI.
So, how do you know if your federated learning model is actually working? In this decentralized world, success isn't just about a single accuracy score. It's about a much deeper, more thoughtful evaluation—one that proves our AI is not only smart but also responsible, fair, and truly effective for every patient it's designed to help.
The biggest challenge, and honestly, the biggest opportunity, with federated learning in healthcare is that we're training on data that is naturally varied. One hospital’s patient demographics, imaging equipment, and clinical protocols are never going to be identical to another's. This is a huge deal. A model that looks brilliant in one clinic could completely fall apart in another, which makes a simple global accuracy score not just incomplete, but potentially dangerous.
Real success is when a model is tough, fair, and works well everywhere.
Key Metrics for a Holistic Evaluation
To get the full story, we have to look past the usual AI report card. We need a multi-faceted strategy that checks performance at two critical levels: locally, right at the hospital where the data lives, and globally, after all the learnings are combined. This dual perspective is the bedrock of building trust and delivering real clinical value.
We need to focus on metrics that tell us what's really going on:
- Robustness: How does the model hold up when it sees something new or unexpected? A robust model won't get thrown off by images from a brand-new MRI machine or a patient group with slightly different characteristics.
- Fairness and Bias: Does the model work just as well for everyone, regardless of age, gender, or ethnicity? We have to proactively hunt for bias to make sure our AI doesn't amplify existing health inequalities. A successful model is an equitable one.
- Generalizability: This is the ultimate exam. A model that generalizes well performs with consistent accuracy across every single participating hospital. It proves it learned universal medical truths, not just the quirks of one location.
Success in federated learning isn't just about achieving high accuracy. It's about building a model that is consistently accurate, fair, and reliable for every patient population it encounters, no matter where they are.
This approach takes us from a simple "pass/fail" grade to a genuine understanding of how our model will behave in the real world.
To really nail this down, it helps to organize these metrics to see how they all fit together.
Key Metrics for Federated Learning Model Evaluation
Here's a breakdown of the essential metrics you'll need to assess the performance, fairness, and robustness of your federated learning models in a healthcare setting.
| Metric Category | Specific Metric | What It Measures |
|---|---|---|
| Performance | Accuracy, Precision, Recall | The model's ability to make correct predictions and identify true positives while minimizing errors. |
| Robustness | Adversarial Attack Success Rate | The model's resilience against intentionally crafted, misleading data inputs. |
| Fairness | Demographic Parity | Whether the model's predictions are independent of sensitive attributes like age, race, or gender. |
| Efficiency | Communication Overhead | The amount of data transmitted between clients and the central server during a training round. |
| Privacy | Epsilon (ε) in Differential Privacy | The level of privacy guarantee provided; a lower epsilon means stronger privacy protection. |
By tracking these metrics, you get a 360-degree view of your model's health and effectiveness, ensuring it's not just technically sound but also ethically responsible.
Continuous Monitoring and Performance Tuning
A federated learning model isn't something you build once and walk away from. Think of it as a living system that needs constant attention. As new patient data flows into each hospital, the model has to be retrained and re-evaluated to keep it from becoming stale—a problem we call "model drift."
This ongoing cycle of learning, checking, and tuning is what keeps the AI sharp and aligned with the day-to-day realities of clinical practice. Of course, managing the lifecycle of digital assets is just one piece of the puzzle. Healthcare organizations also have to manage their physical hardware, including the secure disposal of medical equipment.
At PYCAD, we know that a great algorithm is only the beginning. That's why we at PYCAD, build custom web DICOM viewers and integrate them into medical imaging web platforms equipped with all the tools needed for this kind of rigorous, ongoing validation. Our platforms give you the power to not only deploy sophisticated models but to continuously measure their success in a transparent and responsible way.
To see how we bring these ecosystems to life, take a look at our PYCAD portfolio.
Your Questions on Federated Learning Answered
Diving into federated learning always sparks some great questions. It’s a completely different way of thinking about AI collaboration, especially in a field as sensitive as healthcare. We've heard many of these questions from clinical leaders, IT specialists, and researchers, so we’ve put together answers to the most common ones.
This is all about clearing up any lingering uncertainties and reinforcing the core ideas that make federated learning in healthcare such a promising path for responsible medical innovation.
How Does Federated Learning Differ From Centralized Data Collection?
The biggest difference comes down to one simple thing: data movement. Or, more accurately, the lack of it.
Traditional AI models demand a massive, central database. All patient data gets pooled together in one place, which instantly creates a single, high-value target for a data breach. Federated learning completely flips that script.
With this approach, the patient data never moves. It stays right where it belongs—securely behind each hospital's firewall. Instead of bringing the data to the model, the AI model travels to the data. It learns locally at each site and then sends back only its mathematical learnings, never the raw data itself.
This "data stays put" principle is what gives it its power. It’s the key to enabling collaboration without compromising patient privacy.
Is Federated Learning Completely Secure?
Federated learning is a massive leap forward for data privacy, but it's important to remember that no single technology is a silver bullet. While the raw patient data is never exposed, more sophisticated, theoretical risks do exist. For example, a determined attacker might try to reverse-engineer insights about the training data from the model's updates, a technique known as a "model inversion attack."
This is why a truly robust strategy never relies on one tool alone. The best implementations combine federated learning with other privacy-enhancing technologies, creating a layered defense. This often includes techniques like Differential Privacy, which adds a tiny amount of statistical "noise" to the model updates, making it practically impossible to trace any learning back to a single individual.
Think of it as building multiple walls of defense around your most sensitive health information.
How Can My Organization Get Started?
Taking that first step is often more straightforward than it seems.
It all starts with identifying a clear clinical problem. What’s a challenge where a larger, more diverse dataset could lead to a genuine breakthrough? From there, it’s about finding like-minded partner institutions and, critically, establishing a strong data governance framework that everyone can agree on.
Finally, you need the right technology partner to build the secure infrastructure that makes it all possible. At PYCAD, we at PYCAD, build custom web DICOM viewers and integrate them into medical imaging web platforms. These systems are the bedrock for launching and managing successful federated learning projects in the real world. We create the secure, intuitive environment where collaborative AI can flourish and deliver tangible results. Check out our portfolio page to see what we've built.
Ready to explore how your organization can pioneer the future of collaborative medical AI? The team at PYCAD is here to help you build the secure, custom platform you need. To see our expertise in action, we invite you to explore our portfolio of advanced medical imaging solutions.





