
Computer vision is the science of teaching computers to see. It’s about giving machines the ability to interpret and understand the visual world much like we do. Using images and videos, they can identify objects, analyze scenes, and even react to what's happening in front of them. It's truly about giving machines one of our most powerful senses: sight.
What Does It Mean to See Like a Machine?
Imagine trying to teach a computer what a "cat" is. It’s not about just showing it a picture. True understanding means it can recognize a cat whether it's a fluffy Persian curled up on a sofa, a sleek Siamese leaping through the air, or even a cartoon sketch.
At its core, computer vision is this very quest: to replicate the incredible complexity of human sight in a machine. It's about moving beyond just capturing pixels to truly understanding the context, meaning, and relationships within an image.
Just like a child learns to identify their pet, a computer vision model learns through exposure. The child sees shapes, colors, and movement, and over time, connects those cues to the word "dog." In a strikingly similar way, these models are trained on massive datasets, learning to spot patterns and make connections on a scale we can barely imagine.
From Raw Data to Real Understanding
This learning process is all about recognizing patterns—the distinct curve of a human smile, the intricate texture of a leaf, or the unique silhouette of a stop sign on a busy street. This isn't just about identifying a single object; it's about building a form of digital perception.
This allows the machine to develop incredible new skills:
- Object Identification: Pinpointing specific items in an image, like a single car in a crowded parking lot.
- Scene Understanding: Grasping the bigger picture, like recognizing the difference between a quiet beach and a chaotic city intersection.
- Activity Recognition: Detecting actions as they unfold, such as a person walking or a ball being thrown.
This leap from raw visual data to genuine, actionable insight is where the magic happens. It turns a simple camera into a smart observer that can analyze, report, and even predict what might happen next.
To give you a clearer picture, let's break down the foundational ideas that power this technology.
Key Concepts in Computer Vision at a Glance
This table offers a quick summary of the core concepts, making them easy to digest.
| Concept | Simple Analogy | Primary Goal |
|---|---|---|
| Image Classification | Sorting photos into albums like "beach" or "city." | Assign a single label to an entire image. |
| Object Detection | Drawing boxes around all the cars in a street photo. | Identify and locate multiple objects within an image. |
| Image Segmentation | Coloring in a specific person in a group photo, pixel by pixel. | Outline the exact shape of an object in an image. |
| Feature Extraction | Describing a face by its key features: eye color, nose shape, etc. | Identify unique, measurable patterns in an image for analysis. |
These building blocks are what enable machines to perform incredibly complex visual tasks.
Where This Technology Is Changing Our World
You already encounter computer vision every day, from the facial recognition that unlocks your phone to the sophisticated systems guiding self-driving cars. For a deeper look into how AI processes visual information, this practical guide to artificial intelligence image analysis is an excellent resource.
Here at PYCAD, we're channeling this incredible power toward one of the most important fields: medical imaging. We build custom web DICOM viewers and integrate them into medical imaging web platforms. By teaching machines to see the subtle, often invisible, details in medical scans, we're helping build a future where diagnoses are faster, more precise, and ultimately, more life-saving. You can explore some of our work on our portfolio.
How a Computer Actually Learns to See
So, how does a machine go from seeing a chaotic sea of pixels to confidently identifying a specific object? It's not magic. Think of it like a detective solving a case—piecing together clues, bit by bit, until a clear picture emerges. It's a structured journey from digital noise to genuine insight.
It all starts with the raw visual data. A camera, a CT scanner, or any visual sensor acts as the system's eyes, capturing the world one frame at a time. To the computer, each image is just a massive grid of numbers, with each number representing the color and brightness of a single pixel.
This first step is called Image Acquisition. It’s the moment the detective arrives on the scene and starts taking photographs. The goal is to gather as much high-quality visual evidence as possible, because everything that follows depends on the clarity of these initial "photos."
The infographic below breaks down this three-step journey from raw image to actionable understanding.
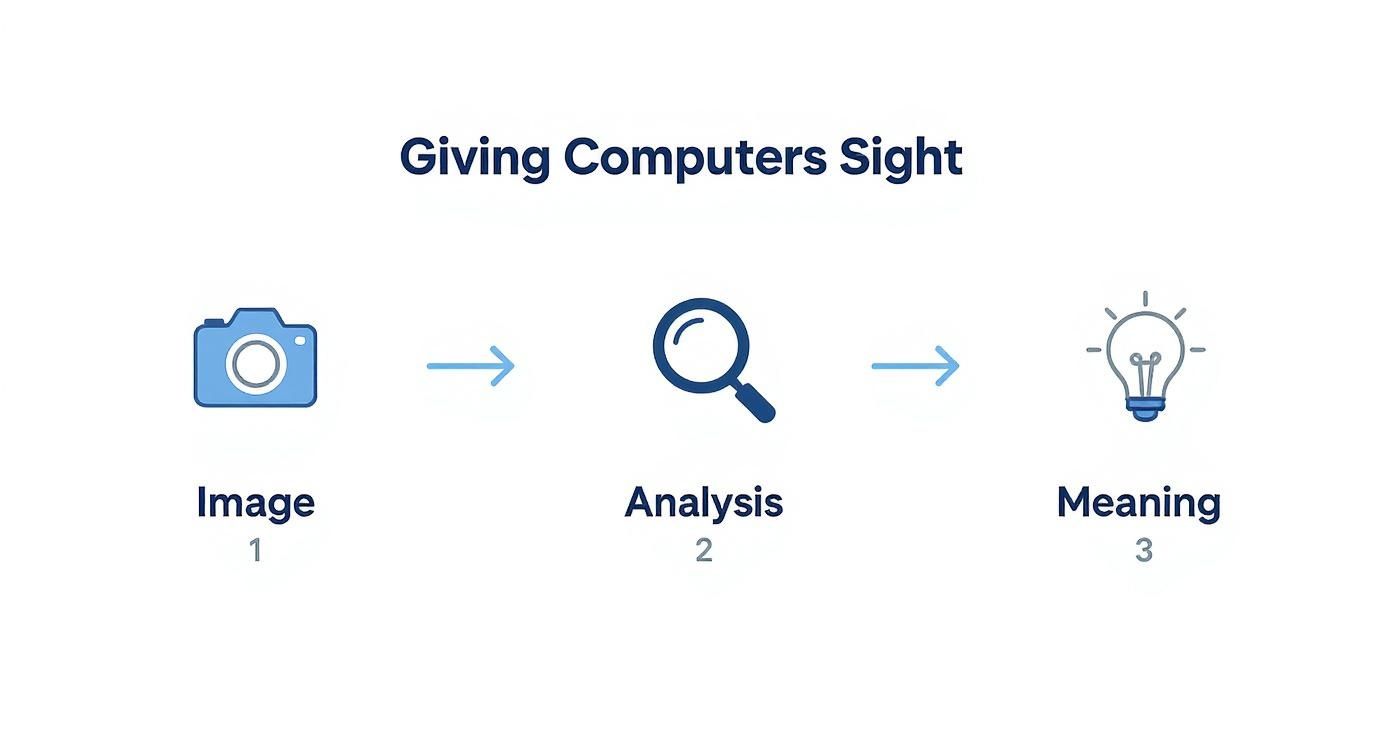
As you can see, it’s a process of analysis and interpretation, designed to turn visual data into confident decisions.
Preparing the Evidence
Once the images are in hand, they’re almost never perfect. They might be blurry, too dark, or cluttered with irrelevant background details. This is where Pre-processing comes in. Think of it as the detective in the darkroom, carefully enhancing a photograph to make a crucial clue pop.
This clean-up phase is essential and often involves a few key steps:
- Noise Reduction: Smoothing out the random specks and graininess that can obscure important features.
- Contrast Adjustment: Making the light and dark parts of an image more distinct to highlight edges and shapes.
- Normalization: Resizing and standardizing images so the model isn't thrown off by irrelevant differences in lighting or scale.
This ensures the algorithm focuses only on what truly matters.
Identifying the Key Clues
With a clean, enhanced image, the system is ready for Feature Extraction. Now the real detective work begins. The algorithm scans the image, not as a whole, but to find and isolate the most important clues—the tell-tale characteristics that will help it make a final identification.
These "features" are the unique patterns that distinguish one thing from another.
In essence, feature extraction is the art of teaching a machine what to look for. It’s about converting a sea of pixels into a concise set of descriptive, measurable data points that represent the image's core content.
For example, if you're identifying a human face, key features might be the distance between the eyes, the shape of the nose, or the curve of the jawline. In a medical scan, a feature could be the specific texture of a tumor or the sharp, clean edge of a bone fracture.
Drawing the Final Conclusion
Finally, we arrive at the most critical stage: Model Training and Inference. Here, the detective takes the clues from the current case and compares them against a vast mental library of past cases to draw a conclusion. The computer vision model does the exact same thing, using the extracted features to make a prediction.
During training, the model is fed thousands, sometimes millions, of labeled images. It painstakingly learns to connect specific sets of features with a certain label. For instance, it learns that a particular combination of edges, textures, and shapes consistently means "cat." Building a solid algorithm for this is a deep topic, and you can learn more by exploring our guide on how to train a machine learning model.
Once trained, the model is ready to perform inference—applying its knowledge to new, unseen images. When it's given the features from a new picture, it calculates the probabilities and makes its final call: "This is a cat with 98% confidence." At PYCAD, we use this exact process in healthcare, where we build custom web DICOM viewers and integrate them into medical imaging web platforms. Our models are trained to see what the human eye might miss, turning medical scans into powerful diagnostic tools you can see in our portfolio.
The Core Techniques That Power Digital Vision
Now that we've walked through the basic workflow, let's pull back the curtain and look at the brilliant techniques that actually bring digital vision to life. These are the foundational methods that give a machine its sight, allowing it to perform specific, meaningful tasks. Getting a feel for them gives you a practical vocabulary for what computer vision can really do.

And make no mistake, these aren't just abstract ideas from a computer science textbook. They're the engines driving a massive technological and economic shift. The global computer vision market was valued at an impressive USD 19.82 billion in 2024, and it's not slowing down. Forecasts from outlets like Grand View Research project it will skyrocket to USD 58.29 billion by 2030, all thanks to the relentless march of automation and AI.
So, let's dive into the three fundamental techniques that form the bedrock of almost every computer vision application out there.
Image Classification: The Digital Sorter
The simplest, yet most essential, task in computer vision is Image Classification. Think of it as a lightning-fast digital mail sorter. Its one and only job is to look at an entire picture and assign it a single, overarching label from a list of categories it already knows.
For instance, you could train a model on thousands of photos to tell the difference between "day" and "night." Over time, the model learns the tell-tale signs of each—bright skies and sharp shadows for "day," dark backgrounds and glowing lights for "night."
This technique answers one simple question: "What is the primary subject of this image?" It doesn't tell you where the subject is, just that it's there.
This is incredibly powerful for any job that requires broad categorization. Think sorting products on a factory line or even identifying different types of medical scans (like classifying an image as an X-ray, MRI, or CT scan). Of course, getting clean data is the first hurdle, and you can learn more about that in our guide on what is image preprocessing.
Object Detection: Finding Needles in a Haystack
While classification gives you the big picture, Object Detection zooms in on the details. It takes a huge leap forward by not only identifying what objects are in an image but also pinpointing their exact locations, usually by drawing a neat rectangular "bounding box" around each one.
Picture a photo of a busy city street. An object detection model wouldn't just say, "This is a street." Instead, it would meticulously find and label every single thing it was trained to see:
- Car 1: Bounding box around a blue sedan.
- Person 1: Bounding box around a pedestrian on the sidewalk.
- Stop Sign: Bounding box around the traffic sign.
- Car 2: Bounding box around a yellow taxi.
This technique tackles a much tougher question: "What objects are in this image, and where are they?" This is the core technology that allows self-driving cars to navigate the world, identifying other vehicles, people, and obstacles in the blink of an eye.
Image Segmentation: The Digital Artist
Finally, we arrive at Image Segmentation, the most precise and artist-like of these core techniques. If object detection draws a rough box around something, image segmentation is like using a digital scalpel to trace its exact outline, pixel by pixel. It provides a profoundly detailed map of an image's contents.
This method creates a precise "mask" for each object, separating it from the background and everything else with incredible accuracy. It generally comes in two flavors:
- Semantic Segmentation: This gives every single pixel in an image a category. In a landscape photo, it might color all the "sky" pixels blue, all the "tree" pixels green, and all the "road" pixels gray.
- Instance Segmentation: This is even smarter. It not only classifies each pixel but also knows the difference between separate objects of the same type. In our street photo, it would color each individual person with a different shade, recognizing them as unique entities.
This level of detail is absolutely critical in fields like medical imaging. Here at PYCAD, this is our bread and butter. Segmentation models can precisely outline a tumor on an MRI scan, giving doctors an exact map for surgery or treatment. We build custom web DICOM viewers and integrate them into medical imaging web platforms, turning this pixel-perfect analysis into real, life-saving clinical tools. You can explore some of our proudest projects in our portfolio.
Transforming Healthcare with Medical Image Analysis
If there’s one place where computer vision’s impact feels truly personal, it’s in healthcare. This is where algorithms stop identifying cats and cars and start seeing the subtle, often life-saving, details inside the human body. Medical image analysis is a massive step forward, giving doctors a new kind of sight to make diagnoses that are faster, more accurate, and more confident.
This technology is essentially teaching machines to read the complex visual language of medical scans—from the grey landscapes of an X-ray to the intricate layers of an MRI. The goal is to have them analyze this data with a speed and consistency that perfectly complements human expertise, turning them into an invaluable partner in patient care.
And this isn't just theory. It's happening in clinics right now.
A New Era of Diagnostic Precision
At its heart, computer vision in medicine is about spotting patterns that are incredibly difficult, or even impossible, for the human eye to catch every single time. An algorithm can sift through thousands of CT scans and learn the faint textural differences that separate a benign growth from a malignant one.
This amazing capability is being put to work in several critical areas:
- Early Anomaly Detection: Think of it as a tireless second pair of eyes. Algorithms can flag suspicious regions on mammograms or lung CTs that might need a closer look from a radiologist.
- Precise Tumor Outlining: Using segmentation, AI can draw an exact, pixel-perfect border around a tumor. This gives surgeons a precise map for removal and helps radiotherapists target treatment with incredible accuracy.
- Quantitative Measurement: Instead of relying on a doctor's manual estimate, computer vision can measure things like the volume of a heart chamber or the progression of brain atrophy in Alzheimer's patients with perfect consistency, every time.
This isn't about replacing doctors. It's about supercharging their skills with powerful tools. It lets them focus their expertise on the toughest parts of a diagnosis and on crafting the best possible treatment plan for their patients.
This potential is attracting huge investment and sparking growth. The global economy is shifting as AI-powered computer vision takes hold, with the U.S. market alone valued at USD 7.33 billion in 2024. Projections show it rocketing to nearly USD 95.92 billion by 2034, driven by the demand for automation and the sheer explosion of visual data in fields like medicine.
The PYCAD Approach to Medical Vision
At PYCAD, our entire mission is to bring this advanced capability right into the clinical workflow. We build custom web DICOM viewers and integrate them into medical imaging web platforms. Our work is all about closing the gap between cutting-edge AI research and the day-to-day realities of healthcare professionals.
We know that a brilliant algorithm is useless if it’s clunky or difficult to access. That’s why we focus on creating smooth integrations that put AI-driven insights directly at a clinician's fingertips, right inside the software they already use. We’re passionate about advancing patient care by giving them the best tools for the job. You can see examples of this on our portfolio page.
The screenshot below from our portfolio is a great example of our work in action, showing a custom DICOM viewer boosted with AI segmentation tools.

This image shows how AI can automatically segment and highlight specific anatomical structures or diseases, giving doctors clear, measurable data in an instant.
Empowering Clinicians with Actionable Insights
The real magic of medical computer vision is how it turns a flood of complex image data into simple, actionable information. Imagine a radiologist who has to review dozens of scans every day. An AI tool can pre-screen these images, flagging the ones that show potential issues and even providing preliminary measurements.
This lets the human expert work smarter, not just harder, focusing their attention where it matters most. This kind of human-machine collaboration is the future of medicine. It creates a system where technology handles the heavy, repetitive data work, freeing up clinicians to deliver compassionate, expert care.
If you'd like to go deeper, we've written an entire guide on the role of computer vision in healthcare. The journey to fully integrate this technology is just getting started, but its potential to save lives and improve care is undeniable.
Computer Vision Applications Beyond the Clinic
While the breakthroughs in healthcare are truly inspiring, computer vision’s impact reaches far beyond hospital walls. It’s reshaping entire industries and redefining what's possible in our everyday lives. Think of it as the quiet engine driving some of today's most incredible innovations, turning ambitious ideas into reality.
The momentum behind this field is staggering. The global market for AI in computer vision is projected to skyrocket from USD 26.55 billion to an incredible USD 473.98 billion by 2035. This massive growth isn't just about numbers; it's a testament to machines that are finally learning to see, recognize patterns, and react to the world around them much like we do.
The Future of Transportation Is Here
Nowhere is this more apparent than in the automotive industry. Self-driving cars aren't magic—they're powered by a symphony of cameras and sensors, with computer vision acting as the brain that interprets a constant flood of visual information. It’s what lets a car tell the difference between a pedestrian and a lamppost, read a stop sign, or navigate the beautiful chaos of a busy highway.
This is object detection and segmentation working in real-time, making millions of decisions every second to keep passengers safe. The push for advanced driver-assistance systems (ADAS) and fully autonomous vehicles is a huge catalyst, constantly moving the technology forward.
Reinventing the Retail Experience
Computer vision is also completely changing the way we shop. Big retailers are already rolling out cashier-less stores where you can just walk in, grab what you want, and leave. How does it work? A network of cameras overhead uses object recognition to track the items you pick up and adds them to a virtual cart.
The result is a shopping experience with zero friction. But it goes deeper than that. These same systems monitor shelves for low stock, automatically alerting staff to restock popular items.
This isn't just about convenience. It gives businesses powerful insights into how customers move through a store, helping them optimize layouts and make smarter operational decisions.
Perfecting Modern Manufacturing
In manufacturing, precision is everything. Computer vision systems are becoming the ultimate quality control inspectors, spotting microscopic defects on a fast-moving production line that a human eye could easily miss. A camera hovering over a conveyor belt can inspect thousands of parts an hour, flagging tiny cracks, misaligned labels, or subtle color flaws.
This automated process drives up efficiency, cuts down on waste, and ensures only perfect products make it out the door. As computer vision expands into connected factories, understanding the related security challenges in IoT applications is also becoming essential for keeping these smart systems secure.
Cultivating Smarter Agriculture
Even one of the world's oldest practices—farming—is getting a high-tech upgrade. Drones outfitted with multispectral cameras soar over fields, using computer vision to analyze crop health from above. These systems can spot early signs of disease, pests, or dehydration by detecting subtle changes in foliage color that are invisible to us.
This allows farmers to be incredibly precise, applying water or nutrients only where they're needed. Known as precision agriculture, this approach boosts yields while conserving precious resources.
While our team at PYCAD focuses on healthcare—where we build custom web DICOM viewers and integrate them into medical imaging web platforms—these examples show just how versatile this technology is. You can see our specialized work in our portfolio.
Answering Your Questions About Computer Vision
As we've journeyed through what computer vision can do—from its foundational techniques to its incredible real-world impact—a few common questions tend to pop up. This is where we clear up any lingering confusion and make sure the big ideas really stick.
Let's tackle some of the most frequent questions to bring it all together.
What Is The Difference Between Computer Vision and Image Processing?
This is a fantastic question, and there's a simple analogy that helps.
Think of image processing as a high-tech photo editor. Its job is to enhance an image—maybe by sharpening details, adjusting the contrast, or cutting through digital "noise." The goal is to take one image and produce a better, clearer version of it. The output is always another image.
Computer vision, on the other hand, starts where image processing leaves off. It doesn't just improve the image; it tries to understand it. The goal isn't to create a better picture, but to pull out meaningful information. The output isn't an image at all—it's knowledge, a decision, or a piece of data, like a label that says, "This is a cat," or coordinates that pinpoint, "A tumor is located here."
Is Computer Vision The Same As Artificial Intelligence?
Not quite, but they're incredibly close partners. Artificial Intelligence (AI) is the huge, overarching field of science dedicated to building machines that can think, reason, and learn like humans. It's the big umbrella.
Computer vision is one of the most vital disciplines under that AI umbrella. Its specific mission is to give intelligent systems the sense of sight, allowing them to perceive and interpret the world visually.
In short, computer vision is the set of eyes that feeds information to the AI's brain. One makes the other exponentially more powerful.
Does Computer Vision Always Need Huge Amounts of Data?
That used to be the case, and it was a major roadblock for years. Deep learning models, especially when built from the ground up, often needed thousands—sometimes millions—of perfectly labeled images to learn patterns effectively.
Thankfully, things have changed. The field has become much smarter and more efficient.
- Transfer Learning: This is a game-changer. We can take a powerful model already trained on a massive, general dataset (like ImageNet) and then "fine-tune" it on our much smaller, specialized set of images. It’s like hiring an expert who already knows a lot and just needs to learn the specifics of a new job.
- Data Augmentation: We can take a small dataset and multiply its size by creating slightly modified copies of the images we have—flipping them, rotating them, or altering the lighting. This teaches the model to recognize objects in all sorts of conditions.
- Synthetic Data: When real-world data is rare or too sensitive to use, we can now generate realistic computer images to train our models instead.
These modern techniques have drastically lowered the barrier to entry, making it possible to build amazing computer vision tools without a mountain of data.
How Can I Start Learning Computer Vision?
There has never been a better time to jump in, and the best way to learn is by doing. A great first step is getting comfortable with the Python programming language, which is the undisputed king in the AI and machine learning world.
Once you have a handle on Python, start playing with the same libraries the pros use every day. Begin with OpenCV for basic image handling and manipulation. Then, graduate to a powerful framework like TensorFlow or PyTorch to build and train your first neural network.
You’ll find an endless supply of free tutorials and courses online. The key is to start a fun, hands-on project—like building a program that recognizes different types of flowers or a simple face detector—to watch these concepts come alive.
At PYCAD, we live and breathe this work, applying these advanced concepts to solve real-world challenges in healthcare. We build custom web DICOM viewers and integrate them into medical imaging web platforms, empowering clinicians with the kind of AI-driven insights we've discussed. To see how we translate powerful ideas into practical, life-saving tools, we invite you to explore our work at our portfolio page.





