
Welcome to the fascinating world of computer vision, where we're teaching machines to see and interpret the world just like we do. At the heart of this incredible leap forward are Convolutional Neural Networks (CNNs), the powerhouse AI models that finally gave computers a true sense of sight.
Think of it this way: you don't recognize a cat by memorizing a specific photo of one. You recognize it by its features—the pointy ears, the whiskers, the furry texture. CNNs work the same way, learning the essential essence of an object rather than just a static collection of pixels.
A New Way For Machines To See
For years, getting a computer to reliably understand an image felt like an impossible task. The old-school methods relied on rigid, hand-coded rules. An engineer would have to manually define what an "edge" or a "corner" looked like, and these systems were incredibly fragile. A simple shadow, a slightly different angle, or a change in lighting could completely throw them off.
This is where CNNs completely changed the game. Instead of being spoon-fed rules, they learn directly from visual data, discovering patterns on their own. It’s a beautifully layered process that mirrors our own brain's visual cortex. They start small, identifying simple things like lines and colors. Then, they combine those simple patterns to recognize more complex shapes—like an eye or a nose—until they can confidently identify a complete face or a car.
The Spark That Ignited Modern AI
The real "aha!" moment for CNNs came in 2012 at the ImageNet competition, a massive challenge for image recognition systems. An architecture called AlexNet didn't just win; it blew the competition out of the water. It dropped the error rate from 26.2% down to an incredible 15.3%, a massive leap that sent shockwaves through the AI community.
That single event was the catalyst. It kicked off an explosion of research and development. By 2017, over 90% of new computer vision research was built on CNNs. Today, they are the quiet workhorses behind technologies that process billions of images every single day.
To give you a clearer picture, let's break down the core ideas we'll be exploring.
Core CNN Concepts at a Glance
This table offers a quick snapshot of the foundational concepts that make CNNs so powerful. We'll dive deep into each of these throughout this guide.
| Concept | Analogy | Primary Function |
|---|---|---|
| Convolution | A magnifying glass scanning for features | Detects patterns like edges, corners, and textures in an image. |
| Feature Maps | A set of treasure maps for an image | Visualizes where specific features (like "whiskers") are located. |
| Pooling | Summarizing a chapter into a single sentence | Reduces image size while keeping the most important information. |
| Activation Function | An "on/off" switch for a neuron | Introduces non-linearity, allowing the network to learn complex patterns. |
These building blocks work together, allowing the network to build a rich, hierarchical understanding of any image it sees.
Beyond Just Pictures
The ability to learn from visual data has opened up a world of possibilities far beyond just tagging photos on social media. From self-driving cars navigating complex city streets to sophisticated medical tools that help doctors spot diseases earlier, CNNs are the driving force behind some of today's most incredible technologies.
A CNN doesn't just "see" an image; it learns to understand the context and relationships within it. This is the crucial shift from simple pixel-matching to genuine feature-learning that gives AI its perceptive power.
Here at PYCAD, we see this power in action every day. We build custom web DICOM viewers and integrate them into medical imaging web platforms, where CNNs become a trusted co-pilot for clinicians, helping them identify anomalies in scans with remarkable precision.
While CNNs are a massive part of computer vision, they are also a key component of the broader AI revolution in business that is reshaping entire industries.
The Building Blocks of AI Vision
To really get how a computer learns to "see," you have to pop the hood and look at the engine that makes it all possible. A Convolutional Neural Network isn't just one big, complicated thing; it's more like a perfectly organized team of specialists, where each layer has a very specific job. Working together, they turn a meaningless grid of pixels into a high-level concept we understand, like "cat" or "tumor."
Think of it as an assembly line for visual understanding. The raw material is the pixel data from an image. As this data travels down the line, each station—or layer—refines it, summarizes it, and pulls out key information until a clear, final prediction comes out at the end. The three core stations on this visionary assembly line are the Convolutional, Pooling, and Fully Connected layers.
This visual shows exactly how a CNN deconstructs an image, starting with raw pixels and building up to recognizable features, until it finally knows what it's looking at.
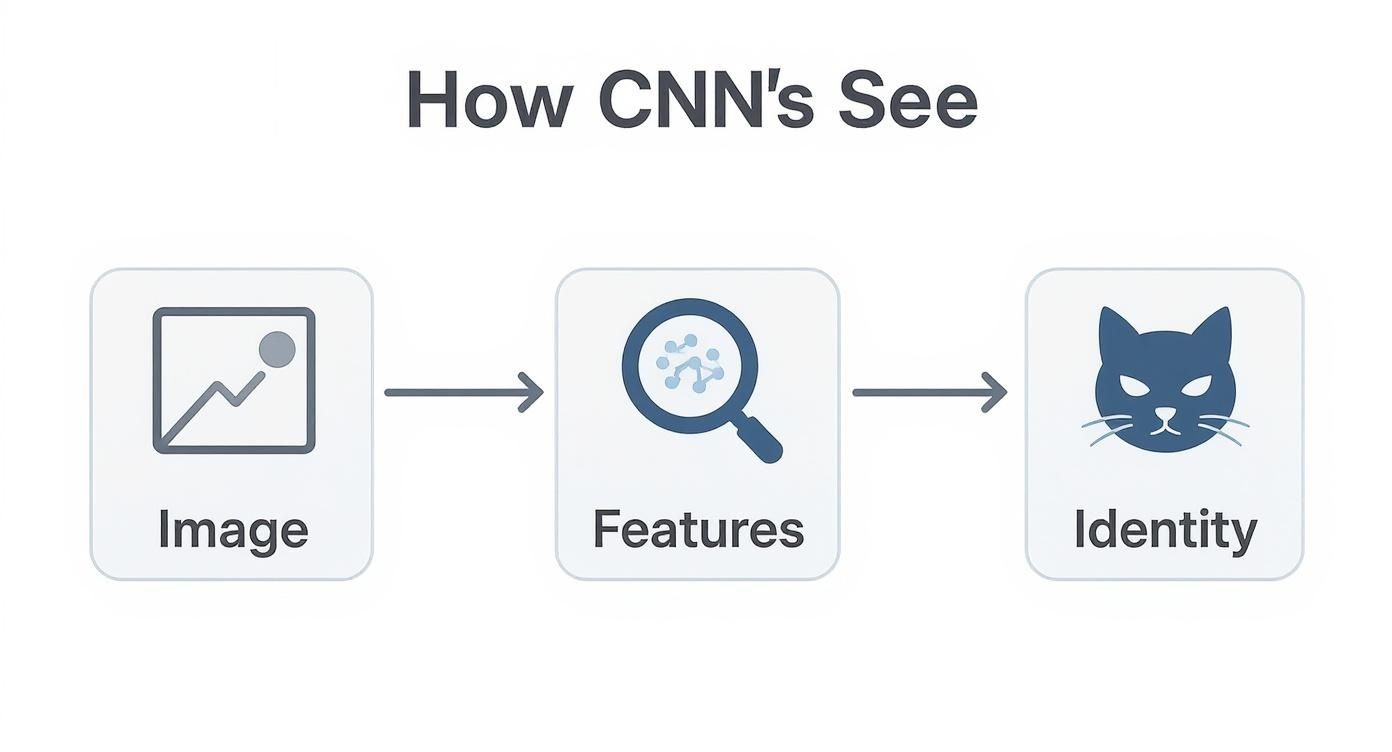
It’s a journey from seeing simple patterns to constructing a complete understanding of an object.
The Feature Detectors
The first stop, and the real heart of the operation, is the Convolutional Layer. Imagine you're giving the network a whole toolbox of tiny, specialized magnifying glasses. One is designed to find vertical edges. Another is built to spot horizontal lines. Others look for specific colors or textures. In CNN lingo, these magnifying glasses are called filters or kernels.
These filters slide systematically across every single part of the input image, hunting for the one pattern they're tuned to find. When a filter gets a match—like a sharp vertical edge—it lights up, creating a strong signal in a corresponding map called a feature map. This whole process, known as convolution, generates a stack of maps that highlight where all the simple, foundational features are located in the original image.
The Summarizer
After the convolutional layer has found thousands of edges, curves, and textures, the network is swimming in highly detailed information. This is where the Pooling Layer (usually Max Pooling) comes in to act as an intelligent summarizer. Its mission is to shrink the feature maps down to a more manageable size while hanging on to the most important bits of information.
It works by sliding a small window over the feature map and grabbing only the strongest signal—the maximum value—in that little area. This has two brilliant effects:
- Efficiency: It dramatically cuts down on the amount of data the network has to chew on, making it faster and less demanding on the hardware.
- Robustness: It helps the network become more resilient to small shifts in the image. By focusing on the presence of a feature rather than its exact pixel location, the network can still recognize an object even if it’s slightly moved or rotated.
This step is absolutely crucial for building a more general, high-level understanding of an object, without getting bogged down in pixel-perfect details.
The Decision-Maker
After going through several rounds of convolution and pooling, the network has built a rich, abstract representation of what's in the image. The last piece of the puzzle is the Fully Connected Layer. This layer is like the network's brain, taking all those high-level features and making the final decision.
A fully connected layer connects every neuron from the previous layer to every one of its own neurons, allowing it to weigh all the evidence and make a sophisticated final prediction.
It looks at the combined patterns—"if I see features A, B, and C, there's a 98% chance this is a cat"—and spits out a probability score for every possible category. This is where the final classification happens, turning a complex web of features into a simple, direct answer.
This layered approach was a huge leap forward. Back in the late 1980s, CNNs introduced the idea of parameter sharing, which drastically cut down the number of connections needed. For a 256×256 image, a single convolutional layer might need less than 1,000 weights, whereas an old-school fully connected network would have required millions. This efficiency is what opened the door for incredibly deep models like ResNet, which achieved a top-5 error rate of just 3.57% on ImageNet—officially surpassing human-level performance.
Here at PYCAD, we use these very principles to build custom web DICOM viewers that integrate into medical imaging platforms, helping clinicians analyze complex scans. To truly appreciate how CNNs work, it helps to first understand the underlying neural networks that serve as their foundation.
How a CNN Learns to See
A brand-new Convolutional Neural Network is a blank slate. It can't tell a cat from a car. It has to learn how to see, much like a child learning to recognize objects for the first time. This learning process isn't magic; it's a brilliant, iterative cycle of guessing, checking, and correcting that transforms the network from an ignorant machine into a visual expert.
It all starts with a guess. You show the network an image, and it passes through all the layers in a process called forward propagation. The network looks at the pixels, picks out what it thinks are important features, and spits out a prediction. This is its best shot based on what it knows—which, at the beginning, is absolutely nothing.

Unsurprisingly, these initial guesses are almost always wrong. And not just a little wrong—wildly wrong. The network might see a clear picture of a dog and confidently label it a bicycle. This is where the real learning begins.
Measuring Mistakes with the Loss Function
To get smarter, the network needs feedback. It needs to know just how far off its guess was. This is where the loss function comes in. Think of it as a strict but fair teacher grading the network's homework. It calculates the gap—the "error" or "loss"—between the network's prediction ("bicycle") and the actual, correct label ("dog").
A big number means a big mistake. A small number means the guess was getting warmer. This single value is the most important piece of information the network receives, and the entire goal of training is to make this number as small as possible over thousands and thousands of examples.
Correcting the Course with Backpropagation
Once the error is calculated, the network does something remarkable: backpropagation. This is the network's moment of reflection. It retraces its steps to figure out exactly which of its internal connections led to the bad guess.
The error value is sent backward through the network, layer by layer. An algorithm then makes tiny adjustments to the network's internal knobs and dials—its weights and biases. Connections that pushed the network toward the wrong answer are nudged down, while connections that might have helped are strengthened. It's a subtle but powerful process of self-correction.
This happens over and over again, for thousands, sometimes millions, of images. With every cycle, the adjustments get more and more refined.
What starts as a random jumble of feature detectors slowly evolves. The network's filters begin to recognize specific textures, then simple shapes, and eventually complex objects. Its vision sharpens with every single iteration.
This relentless cycle of refinement is what builds a CNN's power. The process of checking its work is so fundamental that it has its own dedicated stage; you can dive deeper into this in our guide on what is model validation.
The Three Pillars of CNN Training
So, to boil it all down, the entire learning journey rests on three core ideas that work together in a continuous loop, turning raw data into genuine expertise.
- Forward Propagation: The network takes in an image and makes a guess.
- Loss Calculation: A loss function scores how wrong that guess was.
- Backpropagation: The error is sent backward to intelligently adjust the network’s internal wiring.
This guess-check-correct cycle repeats for every single image in the training data. Over time, the CNN builds a sophisticated internal map of the visual world.
Here at PYCAD, we put this powerful training process to work building AI solutions for healthcare. We develop custom web DICOM viewers and integrate them into medical imaging web platforms, where these highly-trained CNNs can help clinicians make faster, more confident decisions. When you understand this learning journey, you start to see just how AI develops its incredible ability to perceive our world—one corrected mistake at a time. To see our work in action, feel free to browse our portfolio page.
Landmark CNN Architectures
Not all CNNs are created equal. As computer vision has matured, a few key architectural blueprints have emerged as genuine game-changers. Each one solved a critical roadblock, unlocking a whole new level of performance and shaping the AI-powered world we live in today.
The story of the modern CNN wasn't a sudden flash of inspiration but a slow, steady climb built on decades of brilliant work. In fact, the core ideas trace back to 1980 with the neocognitron, an early predecessor. But the real breakthrough came in 1989 when Yann LeCun and his team developed the first truly practical CNN to read handwritten digits. It achieved an error rate of under 1% on the famous MNIST dataset—a result that was simply unheard of at the time.
This early work was foundational. It proved that CNNs could understand the spatial layout of an image, preserving the relationships between pixels that older networks lost. By combining convolutional layers, weight sharing, and pooling, they could efficiently spot local features like edges and curves, setting the stage for everything that followed. You can dive deeper into the foundational history of convolutional neural networks on Wikipedia.
This pioneering research paved the way for the icons of deep learning.
LeNet-5: The Original Pioneer
Long before "CNN" became a common term in tech, there was LeNet-5. Developed back in the 1990s, this was one of the very first architectures to successfully use convolution and pooling to solve a real-world problem: reading handwritten numbers on bank checks.
Its design was wonderfully simple yet incredibly effective. LeNet-5 established the classic pattern of stacking convolutional and pooling layers to gradually shrink the image while extracting more and more complex features. It was a revelation, showing that a neural network could learn to see hierarchical patterns directly from raw pixels—a concept that remains the beating heart of every modern CNN today.
AlexNet: The Game Changer
For years, CNNs were mostly a niche academic interest. That all changed in 2012 with AlexNet. This model didn't just win the prestigious ImageNet competition; it completely demolished the competition, kicking off the modern deep learning era with a bang.
What made AlexNet so special? It came down to a few key innovations that are now standard practice:
- It Went Big: AlexNet was much larger and deeper than its predecessors, proving that scale was the key to tackling massive, real-world image datasets.
- It Used ReLU: It popularized the Rectified Linear Unit (ReLU) activation function, which helped solve the dreaded vanishing gradient problem and let the network train dramatically faster.
- It Embraced GPUs: The creators trained it on powerful GPUs, a move that made it practical to train such a huge model without waiting for months.
AlexNet was the spark that ignited the deep learning revolution. It proved, without a doubt, that deep convolutional networks were the future of computer vision.
The impact was immediate and profound, inspiring a gold rush of research and investment that’s still going strong.
ResNet: The Deep Dive
As researchers pushed the limits, building deeper and deeper networks, they hit a strange wall. After a certain point, simply adding more layers actually started to hurt performance. This is where the Residual Network (ResNet), introduced in 2015, came in with a breathtakingly simple yet brilliant solution.
ResNet's magic ingredient was the "skip connection." These connections act like a highway, creating a shortcut that allows the gradient to flow directly through the network, bypassing several layers. This simple trick made it possible to train incredibly deep networks—some with over 150 layers—that not only worked but set new world records for accuracy.
Comparison of Landmark CNN Architectures
These groundbreaking models weren't just isolated successes; they were stepping stones, each building upon the last. The table below offers a quick look at how these architectures pushed the boundaries of what was possible in computer vision.
| Architecture | Year Introduced | Key Innovation | Primary Use Case |
|---|---|---|---|
| LeNet-5 | 1998 | First practical use of CNNs for image classification. | Handwritten digit recognition (MNIST). |
| AlexNet | 2012 | Deep architecture, ReLU activation, GPU training. | Large-scale image classification (ImageNet). |
| VGGNet | 2014 | Uniform 3×3 convolutions for simplicity and depth. | Object recognition, feature extraction. |
| GoogLeNet | 2014 | "Inception module" for computational efficiency. | Image classification with reduced parameters. |
| ResNet | 2015 | "Skip connections" to enable very deep networks. | State-of-the-art for most vision tasks. |
From the simple elegance of LeNet-5 to the staggering depth of ResNet, this evolution highlights a clear trend: finding clever ways to build deeper, more powerful, and more efficient networks.
These architectures are far more than historical footnotes; they are the bedrock of modern computer vision. The principles they established are now at the core of advanced applications, including the systems we build at PYCAD. We create custom web DICOM viewers and integrate them into medical imaging web platforms, where deep, efficient CNNs help clinicians analyze complex medical scans with greater precision.
To see how these powerful models are applied in real-world healthcare solutions, take a look at our portfolio page.
CNNs in the Real World
All the theory and landmark architectures are fascinating, but the real magic of Convolutional Neural Networks happens when they step out of the lab and start solving profound, real-world problems. This is where the code and math truly come to life, creating tangible, often life-changing, results. You'll find CNNs working quietly behind the scenes everywhere, from helping farmers spot crop disease to giving self-driving cars the ability to "see" the road.
But if there's one field where their impact has been truly monumental, it's healthcare—especially medical imaging. In hospitals and clinics around the world, CNNs are becoming a trusted partner for clinicians, offering a second set of eyes trained on an impossible amount of data.
Let's be clear: this isn't about replacing the incredible expertise of doctors. It's about augmenting their skills. Think of it as a powerful collaboration between human intuition and machine precision.
A New Frontier in Medical Diagnostics
Picture a radiologist, deep in concentration, scanning hundreds of CTs or MRIs every single day. They're looking for those tiny, almost invisible signs of disease—a task where the stakes couldn't be higher. Now, imagine a CNN working right alongside them, a silent assistant that has learned from millions of anonymous scans to spot the faintest patterns that often signal the early stages of a tumor or another anomaly.
This isn't science fiction; it's the reality of medicine today. These networks are already making a difference.
They can:
- Detect Tumors: By analyzing scans, CNNs can highlight suspicious growths that might otherwise be missed, drastically improving the odds of early detection.
- Segment Organs: They can precisely outline organs and lesions, which is an absolute game-changer for planning surgeries and radiation therapy.
- Predict Disease Progression: They can even identify subtle biomarkers in images that help forecast how a condition might evolve.
The results speak for themselves. Studies have shown CNNs can match, and sometimes even surpass, human experts in certain diagnostic tasks. For instance, some models can identify diabetic retinopathy from retinal photos with over 95% accuracy, helping to save the sight of thousands.
Empowering Clinicians with Integrated AI
Of course, having a brilliant algorithm is only half the battle. The real key is weaving this technology seamlessly into the daily workflow of a busy clinic. At PYCAD, this is what we live and breathe. We specialize in building custom web DICOM viewers and integrate them into medical imaging web platforms, designed to put the power of AI right at a doctor's fingertips.
This means a clinician can pull up a patient's scan in a familiar viewer, and in the background, a trained CNN is analyzing that same image in real time. It can flag potential areas of concern instantly, turning a standard diagnostic tool into an intelligent assistant. This fusion of human expertise and AI insight just makes the entire process stronger and more efficient.
The goal of AI in medicine is not to create an artificial doctor, but to build an intelligent assistant that amplifies a doctor's own skills and intuition. It provides a second opinion, a safety net, and a source of data-driven confidence.
By building these integrated platforms, we're helping medical professionals tap into AI-powered insights without having to overhaul how they work. It’s all about making incredible technology accessible, intuitive, and genuinely helpful in the moments that matter.
What we've talked about here is just scratching the surface. To see how these ideas come together in real-world healthcare solutions, we’d love for you to take a look at our portfolio page.
Where Do You Go From Here?
You’ve made it through the core of Convolutional Neural Networks, but your journey into the incredible world of computer vision is really just getting started. We've peeled back the layers on concepts like convolution, pooling, and training, turning what might have seemed like abstract math into practical, powerful tools. You now have the groundwork to see AI not as some kind of magic, but as a brilliant and logical system that learns, step by step.
Think of this knowledge as your launchpad. Computer vision is always pushing forward, with amazing new developments like vision transformers and generative AI constantly redefining the art of the possible. The principles you've grasped here are the very foundation you'll need to understand and build with these future innovations.
Turning Knowledge into Action
The best part comes now: putting what you’ve learned to work. It doesn’t matter if you're aiming to be a data scientist or are just fascinated by technology—the path ahead is wide open. To help you get your hands dirty, here are a few great places to start:
- Explore Open-Source Projects: Head over to platforms like GitHub and look for real-world CNN projects. You can learn a ton just by reading through the code, and even more by trying to contribute.
- Take an Online Course: Well-regarded learning platforms have structured courses that pick up where we left off, complete with coding exercises that let you learn by doing.
- Play with Pre-trained Models: Why reinvent the wheel? Famous architectures are often free to use. Grabbing one and testing it on a new dataset is one of the best ways to build your intuition.
The biggest breakthroughs happen when curiosity meets action. The best way to truly understand convolutional neural networks is to start building, experimenting, and solving real problems with them.
At PYCAD, we're all about channeling this power into real-world healthcare solutions. We build custom web DICOM viewers and integrate them into medical imaging web platforms, turning the insights from AI into practical tools that help clinicians every day. Our work proves just how much potential is waiting to be unlocked when these concepts are applied with purpose.
To see how we bring the power of CNNs to life, we invite you to check out our work on our portfolio page. Your next great idea is out there waiting to be built.
Burning Questions About CNNs
As we dig deeper into how machines learn to see, a few questions always seem to pop up. Let's tackle some of the most common ones to help clear the air and sharpen your understanding of Convolutional Neural Networks.
What’s the Big Deal? How Is a CNN Different From a Regular Neural Network?
The magic is all in how they process information. A standard neural network is a bit clumsy with images; it takes a picture and flattens it into one long, one-dimensional line of pixels. Imagine trying to understand a detailed map after it’s been run through a paper shredder—all the crucial spatial context is lost.
A CNN, on the other hand, is built with vision in mind. It sees an image as it is: a grid of pixels. Its convolutional layers act like a set of eyes, scanning across the image to find local patterns—edges, textures, and shapes. Because it understands that neighboring pixels are related, it’s vastly more effective at making sense of visual data.
Do I Need a PhD in Math to Get This?
Not at all. While CNNs are powered by some serious math like calculus and linear algebra under the hood, you don't need to be a mathematician to use them effectively. Modern frameworks like TensorFlow and PyTorch do all the heavy lifting for you.
Your real goal should be building a strong intuition for what each part does. Think of a loss function as a guide telling the network how wrong it is, and backpropagation as the process of learning from those mistakes. This conceptual grasp is far more valuable for building real-world solutions than memorizing equations.
Are CNNs a One-Trick Pony for Images?
Absolutely not! While they earned their fame by conquering image recognition, the core idea of finding local patterns is incredibly flexible. CNNs are superstars with any data that has a grid-like or sequential structure.
- 1D CNNs: These are fantastic for analyzing time-series data. Think about spotting patterns in an audio waveform or detecting anomalies in sensor readings from a machine.
- 3D CNNs: Perfect for navigating volumetric data. This is huge in medical imaging, where they can analyze 3D CT scans or MRI videos to understand depth and changes over time.
- Natural Language Processing (NLP): They can even be used to find meaningful patterns in the sequence of words in a sentence, helping with tasks like text classification.
The principle is the same—find meaningful patterns in local regions. It just turns out that this idea works beautifully for a lot more than just static photos.
At PYCAD, this isn't just theory; it's what we do every day. We build custom web DICOM viewers and integrate them into medical imaging web platforms, transforming raw medical scans into clear, actionable insights for doctors and researchers. To see these powerful concepts in action within real-world healthcare, take a look at our work on our portfolio page.





